SSL: Generative or Contrastive
Why?
Supervised Learning
- relies heavily on expensive manual labeling
- suffers from generalization error, spurious correlations, and adversarial attacks
- The characteristics of different types of falls are not taken into consideration in most of the work on fall detection surveyed. (like age, gender etc.)
SSL
- Training data is automatically labeled by leveraging the relations between different input sensor signals.
- Features
- Obtain “labels” from the data itself by using a “semi-automatic” process.
- Predict part of the data from other parts.
Motivation of SSL
Mainstream of methods
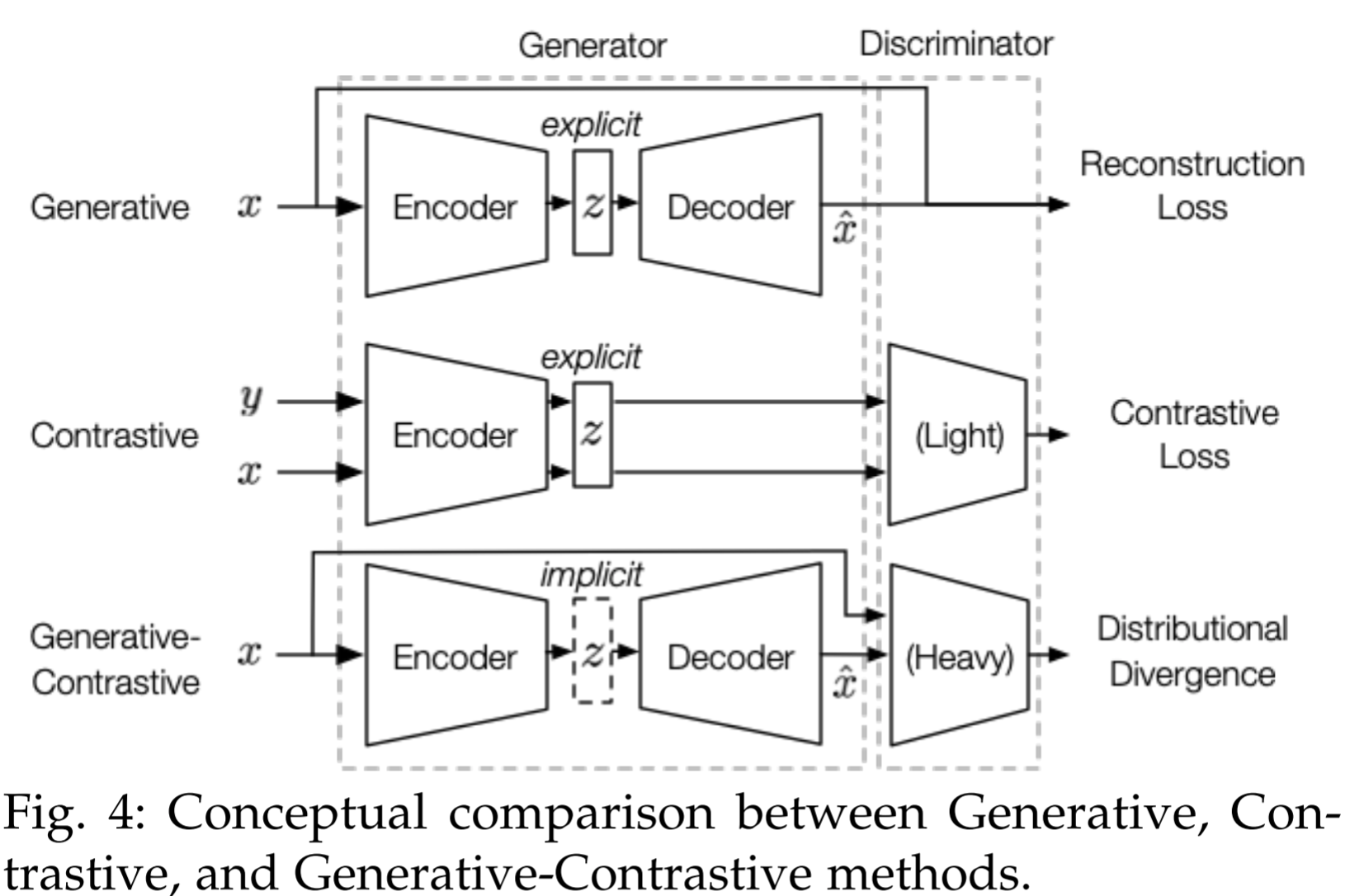
- For latent distribution \(z\): explicit in generative and contrastive methods, and implicit in GAN
- Discriminator: GANs and contrastive have while generative method does not.
- Objectives: generative methods use a reconstruction loss, the contrastive ones use a similarity metric and the GANs leverage distributional divergence as the loss (JS-divergence, Wasserstein distance )
Hints
- Contrastive learning is useful for almost all visual classification tasks: since the contrastive object is modeling the class-invariance between different image instances.
- The art of SSL primarily lies in defining proper objectives for unlabeled data.
Summary of papers

Outline of this paper
Generative SSL
AR model
- Viewed as "Bayes net", where the probability of each variable is dependent on the previous variables.
- objective: in NLP, usually maximizing the likelihood under the forward autoregressive factorization.
- Examples:
- PixelRNN: lower (right) pixels are generated by conditioning on the upper (left) pixels.
- For 2D images: factorize probabilities according to specific directions, and therefore masked filters
- For raw audio: PixelCNN, wavenet.
- GraphRNN: y decompose the graph generation process into a sequence generation of nodes and edges conditioned on the graph generated so far. The objective is the likelihood of the observed graph generation sequences.
- Pros and cons: can model the context dependency well, but the token at each position can only access its context from one direction .
Flow-based model
- Goal: estimate complex high-dimensional densities from data. It designs the mapping between \(x\) and \(z\) in invertible, but also requires that \(x\) and \(z\) have the same dimension.
- Examples
- NICE and RealNVP design affine coupling layer to parameterize \(f_\theta\).
- GLOW: introduces invertible 1 × 1 convolutions and simplifies RealNVP.
AE model
Basic AE
- RBM can be regarded as a special AE.
- AE model is usually a feed-forward neural network trained to produce its input at the output layer.
- the linear autoencoder corresponds to the PCA method.
- some interesting structures can be discovered by imposing sparsity constraints on the hidden units
Context prediction model (CPM)
- Idea: predict contextual information based on inputs.
- negative sampling is employed to ensure computational efficiency and scalability
- Examples
- CBOW, Skip-Gram, FastText based on CBOW
- DeepWalk: based on a similar context prediction objective. It treats random walks as the equivalent of sentences.
- LINE: aims to generate neighbors based on current nodes. Use negative sampling to sample multiple negative edges to approximate the objective.
Denoising AE model
- Intuition: representation should be robust to the introduction of noise.
- Examples
- MLM (masked language model): randomly mask some of the tokes from the input and then predicts them based on their context information. But it assumes the predicted tokens are independent if the unmasked tokens are given, which does not hold in reality.
- Bert: import a unique token to mask some tokens, but also replace the unique token with original words or random words with a small probability.
- SpanBert: mask continuous random spans rather than random tokens adopted by BERT. It trains the span boundary representations to predict the masked spans.
- ERINE: learn entity-level and phrase-level knowledge and further integrates knowledge in knowledge graphs into language models
- GPT-GNN: asks GNN to generate masked edges and attributes.
Variational AE model
Assumes that data are generated from underlying latent representation. The posterior distribution over a set of unobserved variable \(Z\) given some data \(X\) is approximated by a variational distribution \(q(z|x)\approx p(z|x)\). In variational inference, the ELBO (evidence lower bound) on the log-likelihood of data is maximized during training.
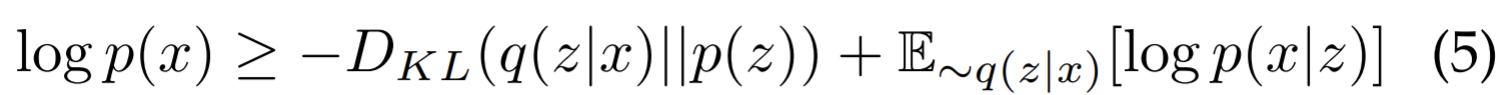
The 1st term of ELBO is a regularizer forcing the posterior to approximate the prior. The second term is the likelihood of reconstructing the original input data based on latent variables.
Examples
- VQ-VAE: aims to learn discrete latent variables motivated by the fact that many modalities are inherently discrete, such as language, speech, and images. VQ-VAE relies on vector quantization (VQ) to learn the posterior distribution of discrete latent variables.
- VQ-VAE-2: enlarge the scale and enhance the autoregressive priors by a powerful PixelCNN prior
- VGAE: VAE combined with GCN as the encoder, with an objective to reconstruct the adjacency matrix of the graph by measuring node proximity.
- DVNE: s Gaussian node embedding to model the uncertainty of nodes. 2-Wasserstein distance is used to measure the similarity between the distributions for its effectiveness in preserving network transitivity
- vGraph: node representation learning and community detection. Assumed that each node can be generated from a mixture of communities.
Hybrid generative models
AR+AE
- Examples
- MADE: modify autoencoder by masking its parameters to respect AR constraints.
- PLM (permutation language model): AR+ auto encoding .
- XLNet: introduces PLM, enables learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order. It also integrates the segment recurrence mechanism and relative encoding scheme of Transformer-XL into pre-training, which can model long-range dependency better that Transformer.
AE + flow-based models
- Examples
- GraphAF: to molecule graph generation as a sequential decision process. Follow flow-based method, it defines an invertible transformation from a base distribution to a molecular graph structure. Dequantization technique is utilized to convert discrete data into continuous data.
Pros and cons
- Ability: recover the original data distribution without assumptions for downstream tasks.
- Shortcomings
- far less competitive than contrastive self-supervised learning in some classification scenarios because contrastive learning’s goal naturally conforms the classification objective: MOCO, SimCLR, BYOL, SwAV.
- Point-wise nature of the generative objective has some inherent defects. The MLE is based on all the samples \(x\) we hope to model and the context information \(c\) is conditionally constrained.
- Sensitive and conservative distribution: when \(p(x|c)\rightarrow 0\), MLE loss becomes super large, making generative model extremely sensitive to rare samples.
- Low-level abstraction objective: the representation distribution in MLE is mostly modeled at \(x\)'s level, while most of the classification tasks target at high-level abstraction.
- Generative - contrastive SSL abandons the point-wise objective.
Contrastive SSL
The contrastive models show the potential of discriminative models for representation. They aim at "learn to compare" through a NCE (noise contrastive estimation ) objective formatted as
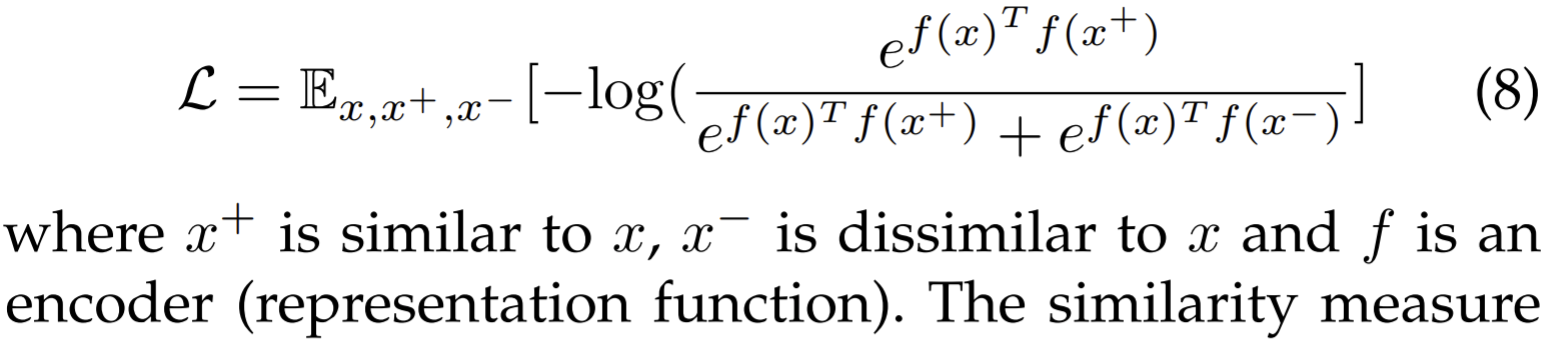
With more dissimilar pairs involved, we have the InfoNCE formulated as
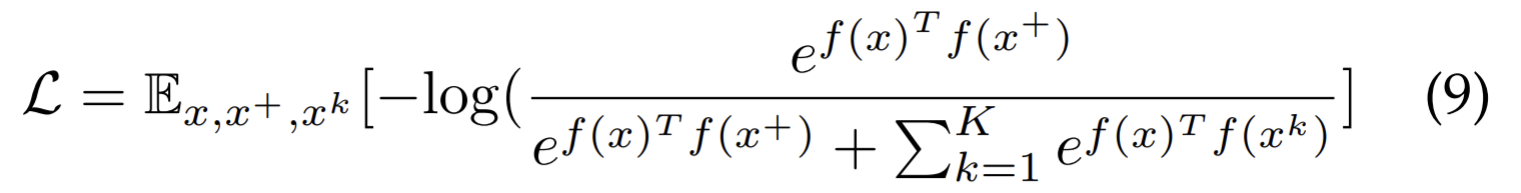
Context-instance Contrast
Also called as global-local contrast, focusing on modeling the belonging relationship between the local feature of a sample and its global context representation. There are two main types of context-instance contrast:
- PRP (predict relative position): learn relative positions between local components. The global context serves as an implicit requirement for predicting these relations. (such as understanding what an elephant looks like is critical for predicting relative position between its head and tail)
- MI (maximize mutual information): learn the direct belonging relationships between local parts and global context. Ignore relative positions between local parts.
Predict relative position
- The PRP is also knowns as pretext task, such as jigsaw, rotation. It may also serve as tools to create hard positive samples.
- Examples
- NSP (next sentence prediction ): for a sentence, the model is asked to distinguish the following and a randomly sampled one. But in RoBERTa, the NSP loss is removed since some argue that NSP may hurt performance.
- ALBERT propose SOP task (sentence order prediction ): two sentences that exchange their position are regarded as a negative sample, making the model concentrate on the semantic meaning’s coherence.
MI
Target at maximizing the association between two variables. To reduce the computation price, in practice, MI is maximized by maximizing its lower bound with an NCE objective
Examples
- Deep InfoMax: maximizing the MI between a local patch and its global context.
- CPC (contrastive predictive coding ): inspired by deep infomax. It maximizes the association between a segment of audio and its context audio. The negative context vectors are taken at the same time.
- AMDIM: enhances the positive association between a local feature and its context. Instead picking a negative image which has the same context, it picks the image which is taken from a different view of the positive image.
- CMC: extends AMDIM, which take the image in several different views as the positive samples, while the negative sample is another irrelevant sampled image. It measure the instance-instance similarity rather than context-instance similarity.
- InfoWord: maximize the mutual information between a global representation of a sentence and n-grams in it. The context is induced from the sentence with selected n-grams being masked, and the negative contexts are randomly picked out from the corpus.
- DGI (deep graph InfoMax): take a nodes representation as the local feature and the average of randomly samples 2-hop neighbors as the context. To generate negative samples on one single graph, DGI corrupt the original context by keeping the sub-graph structure and permuting the node features.
- InfoGraph: follow DGI, learn graph-level representation.
- Similar as CMC: paper learns node and graph representations by maximizing MI between node representations of one view and graph representation of another view and vice versa. They find that graph diffusion is the most effective way to yield augmented positive sample pairs in graph learning.
- In paper , they attempt to unify graph pre-training in two strategies. One is structural prediction at node-level, where they propose context prediction to maximized the MI between the k-hop neighborhood's representations and its context graph. For node-level/graph-level strategy, they propose attribute mask to predict a node's attribute according to its neighborhood, which is a generative objective similar to token masks in bert.
- \(\mathrm{S}^2\)GRL: separate nodes in the context graph into k-hop context subgraphs and maximizes their MI with target node, respectively. (There are k negative samples?)
Cons
Existing graph pre-training work is only applicable for a specific domain, while graph pre-training tends to learn inductive biases across graphs.
Improvements
- Some argue that the models above is only loosely connected to MI by showing that an upper bound MI estimator leads to ill-conditioned and lower performance representations.--> More should be attributed to encoder architecture and a negative sampling strategy related to metric learning.
- And therefore in metric learning: perform hard positive sampling while increasing the negative sampling strategy.
Instance-instance Contrast
- Directly studies the relationships between different samples' instance-level local representations as what metric learning does.
Cluster discrimination
- The motivation is to pull similar images near in the embedding space.
- Examples
- Deep Cluster: leverage clustering to yield pseudo labels and asks a discriminator to predict images' labels. In details, K-means to cluster pseudo labels and then the discriminator predicts whether two samples are from the same cluster and back-propagates to the encoder.
- In DeepCluster, samples are assigned to mutual-exclusive clusters. But LA identifies neighbors separately for each examples.
- DeepCluster optimizes a cross-entropy discriminative loss, while LA employs an objective function that directly optimizes a local soft-clustering metric.
- LA (local aggregation): improve the cluster-based method's boundary.
- LA identifies neighbors separately for each examples.
- LA employs an objective function that directly optimizes a local soft-clustering metric.
- VQ-VAE: similar as LA. For the feature matrix encoded from an image, VQ-VAE substitutes each 1-dimensional vector in the matrix to the nearest one in an embedding dictionary.
- ClusterFit: help in the generalization of other pre-trained models. Introduce a cluster prediction fine-tuning stage similar to DeepCluster.
- SwAV: to improve the time-consuming two-stage training. Use online clustering ideas and multi-view data augmentation strategies into the cluster discrimination approach. To reduce time price, they propose an online computing strategy to label the images in different views.
- M3S: in graph learning. Given little labeled data and many unlabeled data, for every stage, M3S first pretrain as DeepCluster does and then compares these pseudo labels with those predicted by the model being supervised trained on labeled data. . Only top-k confident labels are added into a labeled set for the next stage of semi-supervised training.
- Deep Cluster: leverage clustering to yield pseudo labels and asks a discriminator to predict images' labels. In details, K-means to cluster pseudo labels and then the discriminator predicts whether two samples are from the same cluster and back-propagates to the encoder.
Instance Discrimination
- The prototype is InstDisc.
- Examples
- CMC: adopt multiple different views of an image as positive samples and take another one as the negative. But it's constrained by the idea of Deep Infomax, which only samples one negative sample for each positive one.
- MoCo: leverage instance discrimination via momentum contrast, which substantially increases the amount of negative samples.
- It designs the momentum contrast learning with two encoders (query and key), which prevents the fluctuation of loss convergence in the beginning period
- to enlarge negative samples’ capacity, MoCo employs a queue (with K as large as 65536) to save the recently encoded batches as negative samples.
- But the positive sample strategy is too simple: a pair of positive representations come from the same sample without any transformation or augmentation.
- PIRL: based on MoCo, adds jigsaw augmentation.
- SimCLR: hard positive sample strategy by introducing data augmentation in 10 forms. The augmentation leverages several different views to augment the positive pairs. To handle the large-scale negative samples problem, it chooses a batch size of N as large as 8196. Techniques in SimCLR can also further improve MoCo's performance.
- InfoMin: more into augmenting positive samples. They argue that we should select those views with less mutual information for better augmented views in contrastive learning. To do so, they first propose an unsupervised method to minimize mutual information between views, but this will result in a loss of information for predicting labels, say a pure blank view. Then a semi-supervised method is proposed to find views sharing only label information.
- BYOL: discards negative sampling in SSL but achieves an even better result over InfoMin. They argue that negative samples may not be necessary in this process.
- If we use a fixed randomly initialized network to serve as the key encoder, the representation produced by query encoder would still be improved during training.
- BYOL proposes an architecture with an exponential moving average strategy to update the target encoder just as MoCo does.
- The loss is mean square error, which is robust to smaller batch size.
- The batch size in BYOL is not as critical as what's in MoCo and SimCLR.
- SimSiam: study how necessary is negative sampling.
- They show that the most critical component in BYOL is the stop gradient operation, which makes the target representation stable.
- It converges faster than MoCo, SimCLR, and BYOL with even smaller batch sizes.
- ReLIC: argue that contrastive pre-training teaches the encoder to causally disentangle the invariant content and style in an image.
- They propose to add an extra KL-divergence regularizer between prediction logits of an image's different views.
- GCC (graph contrastive coding): leverage instance discrimination as the pretext task for structural information pre-training.
- For each node, they sample two subgraphs independently by random walks with restart and use top eigenvectors from their normalized graph Laplacian matrices as nodes' initial representations.
- Then they use GNN to encode them and calculate the InfoNCE loss.
- GraphCL: studies the data augmentation strategies, propose four different augmentation methods based on edge perturbation and node dropping. They show that the appropriate combination of these strategies can yield even better performance.
SS contrastive pre-training for semi-supervised self-training
- No matter how self-supervised learning models improve, they are still the only powerful feature extractor, and to transfer to the downstream task, we still need labels more or less.
- In self-training, a model is trained on the small amount of labeled data and then yield labels on unlabeled data. Only those data with highly confident labels are combined with original labeled data to train a new model. We iterate this procedure to find the best model.
- Student-teacher
- The improvements from pre-training and self-training are orthogonal to each other. The model with joint pre-training and self-training is the best.
- SimCLR v2 adopts the conclusion above
- Do SS pre-training as SimCLR v1, with some minor architecture modification and a deeper ResNet.
- Fine tune the last few layers with only 1% or 10% of original ImageNet labels.
- Use the fine-tuned network as teacher to yield labels on unlabeled data to train a smaller student ResNet-50.
Pros and cons
- usually light-weighted and perform better in discriminative downstream applications
- Problems remain to be solved
- Scale to natural language pre-training
- Sampling efficiency: hints from BYOL and SimSiam. The role that negative sampling plays in contrastive learning is still not clear.
- data augmentation: in theory, why data augmentation can boost contrastive learning's performance is still not clear.
Generative-Contrastive (Adversarial) SSL
Adversarial learning learns to reconstruct the original data distribution rather than the samples by minimizing the distributional divergence.
Generate with Complete Input
- Capturing the sample's complete information.
- To extract the implicit distribution out \(p(z)\),
- AAE: the generator in GAN is an implicit autoencoder, which can be replaced by an explicit variational autoencoder (VAE).
- AAE substitutes the KLH divergence function for a discriminative loss.
- AAE: the generator in GAN is an implicit autoencoder, which can be replaced by an explicit variational autoencoder (VAE).
Recover with Partial Input
- Provide models with partial input and ask them to recover the rest parts. Similar as masked bert but this works in an adversarial manner.
- Examples
- Colorization: given one color channel L in an image and predicting the value of two other channels A, B. The encoder and decoder networks can be set to any form of convolutional neural network.
- Inpainting: ask the model to predict an arbitrary part of an image given the rest of it. Then a discriminator is employed to distinguish the inpainted image from the original one.
- SRGAN: follows the same idea in inpainting,
Pre-trained Language model (PTM)
- Focus on maximum likelihood estimation based on pretext task.
- Examples
- ELECTRA: outperform BERT.
- The generator is a small masked language model (MLM)
- The discriminator will predict which words are replaced.
- Training steps: first warming-up the generator by MLM pretext task. Then train with the discriminator.
- WKLM: perform Replaced Token Detection (RTD) at the entity-level.
- ELECTRA: outperform BERT.
Graph learning
- Adopt adversarial training
- ANE (adversarial network embedding) designs a generator that is updated in two stages: the generator encodes sampled graph into target embedding and computes traditional NCE with a context encoder like Skip-gram; discriminator will distinguish embedding from the generator and sampled one from a prior distribution.
- GraphGAN: model the link prediction task and follow the original GANs style discriminative objective to distinguish directly at node-level rather than representation-level.
- GraphSGAN: use the adversarial method in semi-supervised graph learning with the motivation that marginal nodes cause most classification errors in the graph. Between clusters, there are density gaps where few samples exist. They prove that we can complete classification theoretically if we generate enough fake samples in density gaps. The generator will generate fake nodes in density gaps during the training.
Domain adaption and multi-modality representation
- GAN can help on domain adaption: [1], [2], [42], [113].
- Leverage adversarial sampling to improve the negative samples' quality: [16], [138]
Pros and cons
- Challenges
- Limited applications in NLP and graph.
- Easy to collapse
- Not for feature extraction: Contrastive learning is more practical in extraction.
Theory behind SSL
GAN
Divergence matching
- Different divergence functions leads to different GAN variants. Paper discusses the effects of various choices of divergence functions.
Disentangled representation
- GAN shows its superior potential in learning disentangled features empirically and theoretically.
- InfoGAN proposes to learn disentangled representation with DCGAN.
- Since mutual information is hard to compute, they leverage the variational inference approach to estimate its lower bound.
- GAN dissection: apply causal analysis into understanding GAN. They identify the correlations between channels in the convolutional layers and objects in the generated images, and examine whether they are causally-related with the output.
- Paper examines the channels' conditional independence via rigorous counterfactual interventions over them. They show that in BigGAN, it's possible to disentangle backgrounds and objects.
Maximizing Lower Bound
Evidence lower bound

ELBO is the lower bound of the optimization target KL divergence. VAE maximizes the ELBO to minimize the difference between \(q_\phi(z|x),p_\theta(z|x)\).
Mutual information
- Maximizes the MI of the input and its representation with joint density \(p(x|y\) and marginal densities \(p(x),p(y)\).
- Examples
- Deep Infomax maximizes the MI of local and global features and replaces KL-divergence with JS-divergence, which is similar to GAN.
- Instance Discrimination directly optimizes the proportion of gap of positive pairs and negative pairs. One of the commonly used estimators is InfoNCE. And prove that useful to use large negative samples(large values of N. But then the other testify that increasing the number of negative samples does not necessarily help.
- Maximizing the lower bound (MI and ELBO) is not sufficient to learn useful representations.
- MI maximization can be analyzed from the metric learning view. By rewriting the InfoNCE MI as the triplet loss, it is corresponding to the expectation of the multi-class k-pair loss.
Contrastive SS representation learning
Relationship with Supervised learning
How contrastive pre-training benefits supervised learning?
SSL cannot learn more than supervised learning, but make it with few labels.
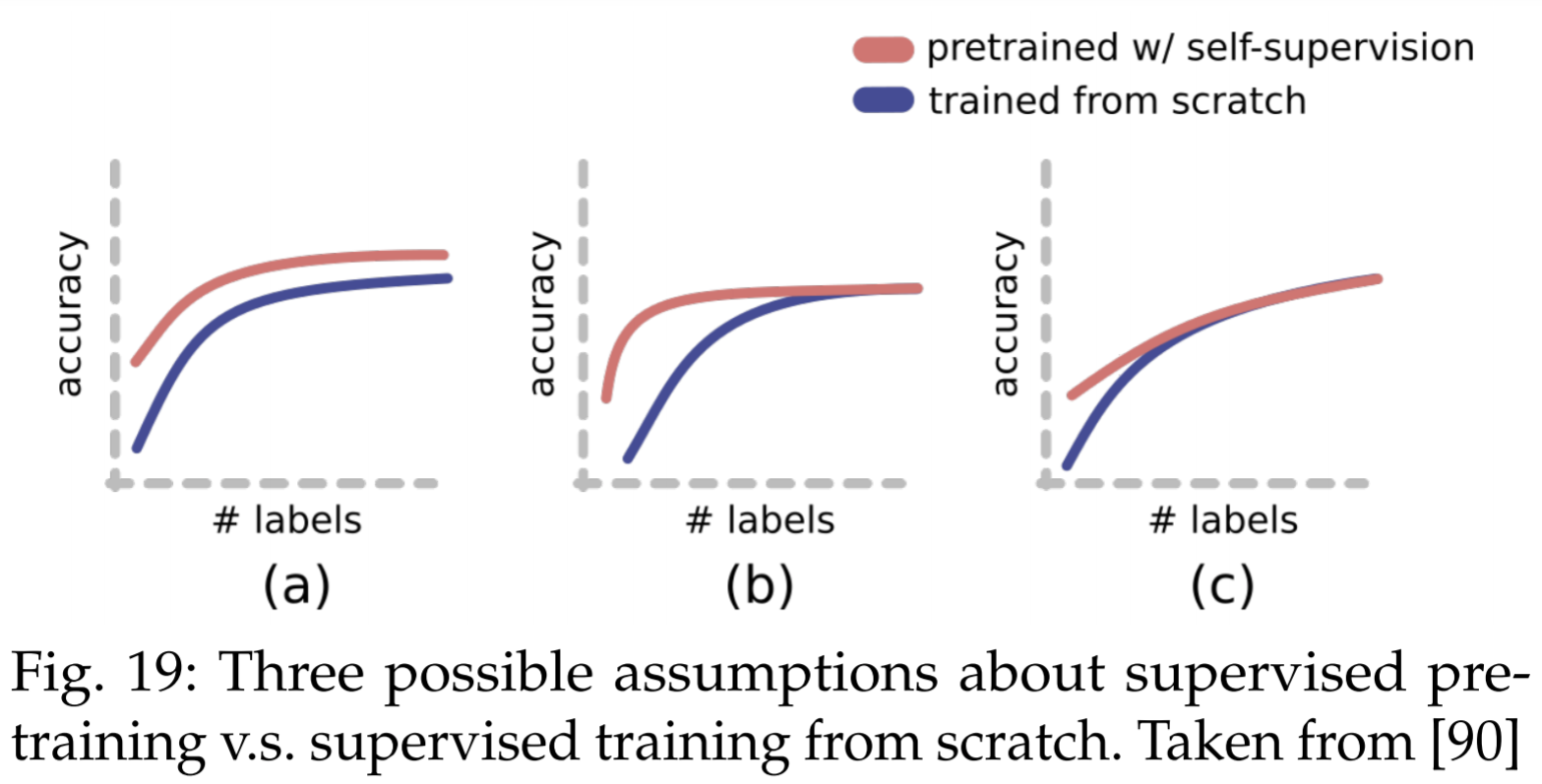
SSL trained neural networks are more robust t adversarial examples, label corruption and common input corruptions. It also benefits OOD detection on difficult, near-distribution outliers, so much so that it exceeds the performance of fully supervised methods.
Understanding Contrastive Loss
Split the contrastive loss into two terms
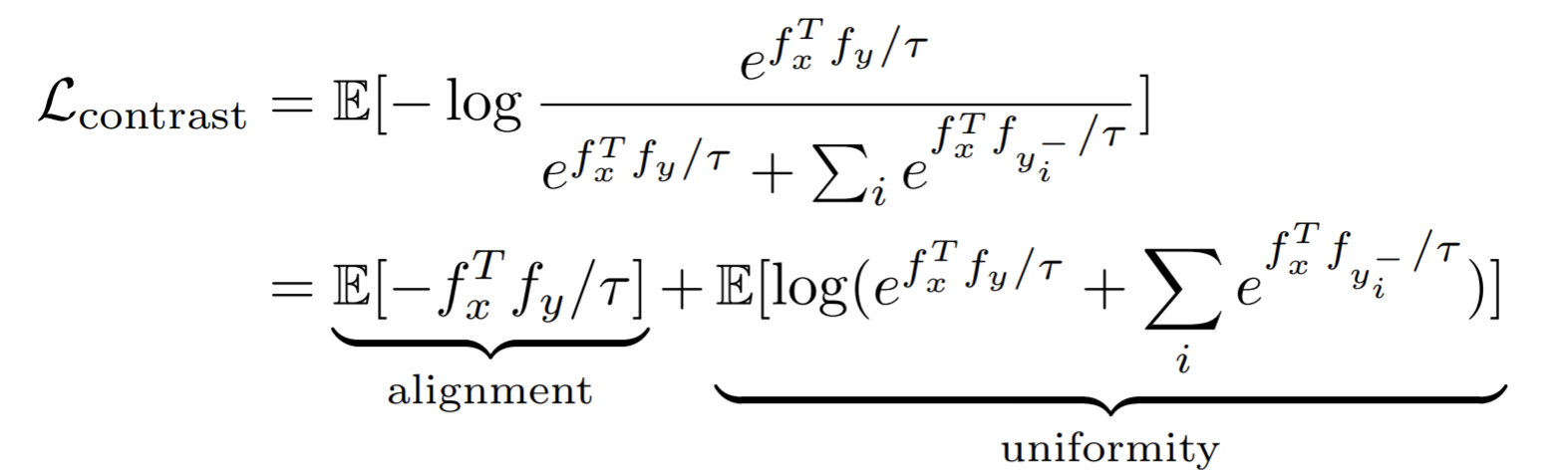
where the first term aims at “alignment” and the second aims at “uniformity” of sample vectors on a sphere given the normalization condition. They show that these two terms have a large agreement with downstream tasks.
- They show that by directly optimizing the two loss, it is consistently better than contrastive loss. And both these terms are necessary for a good representation.
It's doubtful that whether alignment and uniformity are necessarily in the form of upper two losses. We may still achieve uniformity via other techniques such as exponential moving average, batch normalization, regularization and random initialization.
Generalization
It is unclear why the learned representations should also lead to better performance on downstream tasks.
- Paper propose a conceptual framework to analyze contrastive learning on average classification tasks.
- Under the context of only 1 negative sample, it is proved that optimizing unsupervised loss benefits the downstream classification tasks.

- They argue that enlarging the number of negative samples does not hold for contrastive learning and shows that it can hurt performance when the negative samples exceed a threshold.
- Noise Contrastive Estimation(NCE) [49] explains that increasing the number of negative samples can provably improve the variance of learning parameters
Discussion and future directions
- Theoretical foundation
- Transferring to downstream tasks
- pre-training task selection problem: By ALBERT, NSP for bert may hurt its performance.
- NAS to design pre-training tasks for a specific downstream task automatically.
- Transferring cross datasets (inductive learning)
- Exploring potential of sampling strategies
- leverage super large amounts of negative samples and augmented positive samples, whose effects are studied in deep metric learning.
- How to further release the power of sampling is still an unsolved and attractive problem.
- Early degeneration for contrastive learning
- the contrastive objectives often get trapped into embedding spaces’ early degeneration problem, which means that the model over-fits to the discriminative pretext task too early, and therefore lost the ability to generalize.