Paper I: Deep Learning for Anomaly Detection: A Review
Project II: Graph Level Anomaly Detection
Paper III: Multi-Level Anomaly Detection on Time-Varying Graph Data
Paper I: Deep Learning for Anomaly Detection: A Review
Why?
- outlier detection or novelty detection
- Deep anomaly detection aims at learning feature representations or anomaly scores via neural networks for the sake of anomaly detection.
Problem complexities and challenges
Major problem complexities
- Unknownness: Anomalies are associated with many unknowns
- Heterogeneous anomaly classes: one class of anomalies may demonstrate completely different abnormal characteristics from another class of anomalies.
- Rarity and class imbalance: it is difficult to collect a large amount of labeled abnormal instances.
- Diverse types of anomaly:
- Point anomalies: individual instances that are anomalous w.r.t. the majority of other individual instances
- Conditional anomalies: contextual anomalies, also refer to individual anomalous instances but in a specific context.
- Group anomalies: a subset of data instances anomalous as a whole w.r.t. the other data instances.
Main challenges tackled by deep anomaly detection
- CH1: low anomaly detection recall rate: How to reduce false positives and enhance detection recall rates
- CH2: anomaly detection in high-dimensional and/or not-independent data:
- High-dimensional anomaly detection
- Performing anomaly detection in a reduced lower dimensional space spanned by a small subsets of original features or newly constructed features.
- But challenges on identifying intricate (e.g., high-order, nonlinear and heterogeneous) feature interactions and couplings.
- Guarantee the new feature space preserved proper information for specific detection methods.
- Due to the aforementioned unknowns and heterogeneities of anomalies.
- Detect anomalies from instances that may be dependent on each other.
- High-dimensional anomaly detection
- CH3: data-efficient learning of normality/abnormality
- Fully supervised anomaly detection is often impractical.
- Unsupervised methods do not have any prior knowledge of true anomalies. They rely heavily on their assumption on the distribution of anomalies.
- Weakly supervised anomaly detection
- How to learn expressive normality/abnormality representations with a small amount of labeled anomaly data.
- How to learn detection models that are generalized to novel anomalies uncovered by the given labeled anomaly data.
- CH4: Noise-resilient anomaly detection
- Large-scale anomaly-contaminated unlabeled data
- The amount of noises can differ significantly from datasets and noisy instances may be irregularly distributed in the data space.
- CH5:Detection of complex anomalies
- The generation from point anomalies to conditional anomalies and group anomalies
- How to incorporate the concept of conditional/group anomalies into anomaly measures/models.
- The detection of anomalies with multiple heterogeneous data sources.
- CH6: Anomaly explanation
- Have anomaly explanation algorithms that provide straightforward clues about why a specific data instance is identified as anomaly.
- A main challenge to well balance the model’s interpretability and effectiveness.
Addressing the challenges with deep anomaly detection
Preliminaries
- Deep anomaly detection aims at learning a feature representation mapping function \(\phi (·) : X\mapsto Z\) or an anomaly score learning function \(\tau (·): X\mapsto R\) in a way that anomalies can be easily differentiated from the normal data instances in the space yielded by the \(\phi\) or \(\tau\) function.
Categorization of deep anomaly detection
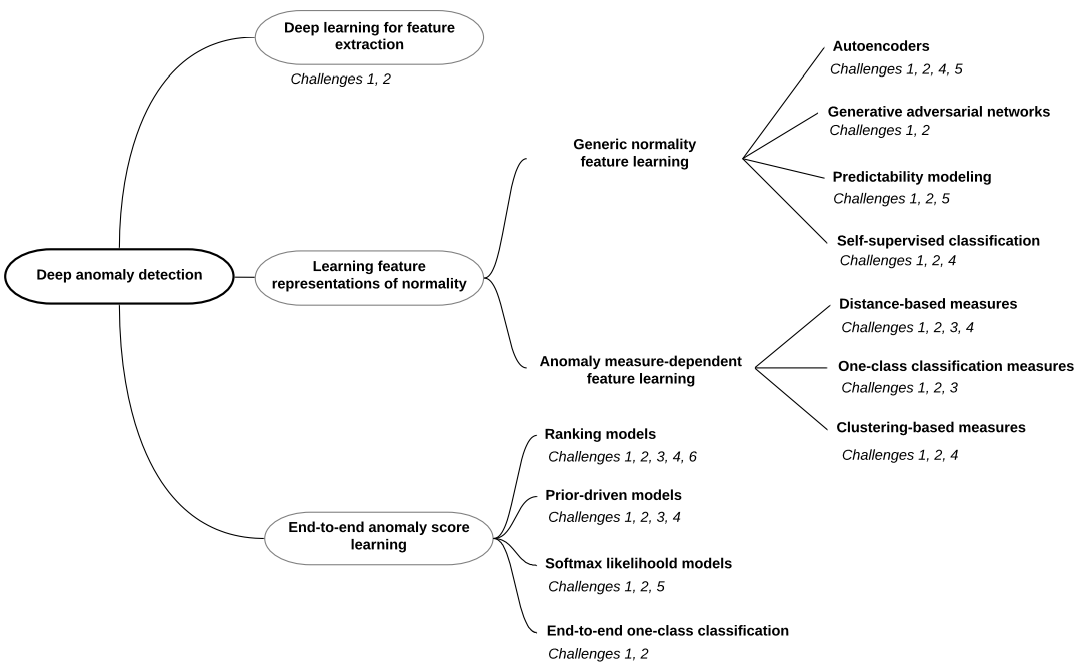
Deep learning for feature extraction
- The deep learning components work purely as dimensionality reduction only.
- Assumptions: The feature representations extracted by deep learning models preserve the discriminative information that helps separate anomalies from normal instances.
- Research lines
- Directly use popular pre-trained deep learning models such as VGG etc.
- An unmasking process: iteratively train a binary classifier to separate one set of video frames from its subsequent video frames in a sliding window, with the most discriminant features removed in each iteration step. The power of unmasking framework relies heavily on the quality of the features.
- Using features extracted from a dynamically updated sampling pool of video frames is found to improve the performance of the framework.
- Pretrained model and fine-tuning.
- Explicitly train a deep feature extraction model rather than a pre-trained model for the downstream anomaly scoring.
- Methods
- Three separate autoencoder networks are trained to learn low-dimensional features for respective appearance, motion, and appearance-motion joint representations for video anomaly detection.
- Unsupervised classification approaches to enable anomaly scoring in the projected space. Use cluster methods to assign pseudo labels and then do one-vs-the-rest classification. The classification probabilities are used to define frame-wise anomaly scores.
- Graph anomaly detection: learn the representations of graph vertices by minimizing autoencoder-based reconstruction loss and pairwise distances of neighbored graph vertices.
- Methods
- Directly use popular pre-trained deep learning models such as VGG etc.
- Advantages
- A large number of state-of-the-art (pre-trained) deep models and off-the-shelf anomaly detectors are readily available.
- Deep feature extraction offers more powerful dimensionality reduction than popular linear methods.
- It is easy-to-implement given the public availability of the deep models and detection methods.
- Disadvantages
- The fully disjointed feature extraction and anomaly scoring often lead to suboptimal anomaly scores.
- Pre-trained deep models are typically limited to specific types of data.
- Challenges Targeted
- The lower-dimensional space often helps reveal hidden anomalies and reduces false positives (CH2).
- May not preserve sufficient information for anomaly detection as the data projection is fully decoupled with anomaly detection.
- Allows to leverage multiple types of features and learn semantic-rich detection models, and then reduce CH1.
Learning feature representation of normality
Generic normality feature learning
- Learns the representations of data instances by optimizing a generic feature learning objective function that is not primarily designed for anomaly detection.

Autoencoders
Aims to learn some low-dimensional feature representation space on which the given data instances can be well reconstructed. The learned feature representations are enforced to learn important regularities of the data to minimize reconstruction errors, anomalies are difficult to be reconstructed from the resulting representations and thus have large reconstruction errors.
Assumptions: Normal instances can be better restructured from compressed space than anomalies.
Formally,

Methods
- Sparse AE: encourage sparsity in the activation units of the hidden layer.
- Denoising AE: learning representations that are robust to small variations by learning to reconstruct data from some predefined corrupted data instances rather than original data.
- Contractive AE: takes a step further to learn feature representations that are robust to small variations of the instances around their neighbors. By adding a penalty term based on the Forbenius norm of the Jacobian matrix of the encoder's activations.
- Variational AE: introduces regularization into the representation space by encoding data instances using a prior distribution over the latent space.
Implementations
- Replicator NNs
- RandNet: learning an ensemble of AEs
- RDA: motivated by robust PCA, it attempts to iteratively decompose term original data into 2 subsets, normal instance set and anomaly set. This is achieved by adding a sparsity penalty \(\ell_1\) or grouped penalty \(\ell_{2,1}\) into its RPCA-alike objective function to regularize the coefficients of the anomaly set.
For more complex data
- Adapting the network architecture to the type of input data, they embeds the encoder-decoder scheme into the full procedure of these methods, such as CNN-AE, LSTM-AE, Conv-LSTM-AE, GCN-AE etc.
- First use AEs to learn low-dimensional representations of the complex data and then learn to predict these learned representations.
- denoising AE is combined with RNNs to learn normal patterns of multivariate sequence data,
Advantages
- The idea of AEs is straightforward and generic to different types of data.
- Different types of powerful AE variants can be leveraged to perform anomaly detection.
Disadvantages
- The learned feature representations can be biased by infrequent regularities and the presence of outliers or anomalies in the training data.
- The objective function of the data reconstruction is designed for dimension reduction or data compression, rather than anomaly detection.
Challenges
- CH2: attributed graph data etc.
- CH1: reduce false positives
- CH4: RPCA
GANs
Some form of residual between the real instance and the generated instance are then defined as anomaly score.
Assumption: Normal data instances can be better generated than anomalies from the latent feature space of the generative network in GANs
Methods
AnoGAN: computational inefficiency in the iterative search of latent representation \(\boldsymbol{\mathrm{z}}\).
- To alleviate the inefficiency
- EBGAN : based on BiGAN, discriminate the pair of instances \((\mathrm{x}, 𝐸(\mathrm{x}))\) from the pair \((𝐺(\mathrm{z}),\mathrm{z})\). EBGAN is extended to ALAD by adding two more discriminators with one discriminator trying to discriminate the pair \((\mathrm{x}, \mathrm{x})\) from $(,𝐺(𝐸())) $and another one trying to discriminate the pair \((\mathrm{z},\mathrm{z})\) from \((\mathrm{z}, 𝐸(𝐺(\mathrm{z})))\).
- fast AnoGAN: share the same spirit of EBGAN.
- ALAD: the extension of EBGAN
- To alleviate the inefficiency
GANomaly: further improves the generator over the previous work by changing the generator network to an encoder-decoder-encoder network and adding two more extra loss function.

Combined with wassertein GAN or adversarially learn end-to-end one-class classification.
Advantages
- Demonstrated superior capability in generating realistic instances, especially on images.
- A large number of existing GAN-based models and theories may be adapted for anomaly detection.
Disadvantages
- The training of GANs can suffer from multiple problems, such as failure to converge and mode collapse.
- The generator network can be misled and generates data instances out of the manifold of normal instances.
- The GANs-based anomaly scores can be suboptimal since they are built upon the generator network with the objective designed for data synthesis rather than anomaly detection.
Challenges
- CH2, CH1
Predictability modeling
Learn feature representations by predicting the current data instances using the representations of the previous instances within a temporal window as the context. The prediction errors can be used to define the anomaly scores
Assumptions: Normal instances are temporally more predictable than anomalies
Methods
FFP: Using like U-net prediction, popular in video anomaly detection.
U-Net as the frame generator, and measure the objective loss by intensity, gradient and optical flow. After training, for a given video frame \(\mathrm{x}\), a normalized Peak Signal-to-Noise Ratio based on the prediction difference is used to define the anomaly score.
Another way is based on autoregressive models that assume each element in a sequence is linearly dependent on the previous elements.
- At the evaluation stage, the reconstruction error and the log-likelihood are combined to define the anomaly score.
Advantages
- A number of sequence learning techniques can be adapted and incorporated into this approach.
- This approach enables the learning of different types of temporal and spatial dependencies.
Disadvantages
- This approach is limited to anomaly detection in sequence data.
- The sequential predictions can be computationally expensive.
- The learned representations may suboptimal for anomaly detection as its underlying objective is for sequential predictions rather than anomaly detection.
Challenges
- CH1&CH2
- CH5
Self-supervised classification
Learns representations of normality by building self-supervised classification models and identifies instances that are inconsistent to the classification models as anomalies.
Evaluate the normality of data instances by their consistency to a set of predictive models, with each model learning to predict one feature based on the rest of the other feature.
Focuses on image data and builds the predictive models by using feature transformation-based augmented data.
Assumptions: Normal instances are more consistent to self-supervised classifiers than anomalies.
Methods
- GT: Like horizontal flipping, translations, and rotations. The classification scores of each test instance w.r.t. different \(𝑇_𝑗\) are then aggregated to compute the anomaly score.
- \(E^3\)outlier : Training data contains normal instances only. UOD
- The gradient magnitude induced by normal instances is normally substantially larger than outliers during the training of such self-supervised multiclass classification models;
- The network updating direction is also biased towards normal instances.
Normal instances often have stronger agreement with the classification model than anomalies.
Negative entropy-based anomaly scores perform generally better than average prediction probability and maximum prediction probability.
Advantages
- They work well in both the unsupervised and semi-supervised settings.
- Anomaly scoring is grounded by some intrinsic properties of gradient magnitude and its updating.
Disadvantages
- The feature transformation operations are often data-dependent. And the operations (rotation) only work on images.
- The consistency-scores are derived upon the classification scores rather than an integrated module in the optimization, and thus they may be suboptimal.
Challenges
- CH1 & CH2
- CH4
Anomaly measure-dependent feature learning
Learning feature representations that are specifically optimized for one particular existing measure. They incorporates an existing anomaly measure \(f\) into the feature learning objective function to optimize the feature representations specifically for \(f\).
Distance-based measure
- Aims to learn feature representations that are specifically optimized for a specific type of distance-based anomaly measures.
- Like DB outliers, \(k\)-nearest neighbor distance, average \(k\)-nearest neighbor distance, relative distance and random nearest neighbor distance. But they fail to work effectively in high dimensional data.
- Assumption : anomalies are distributed far from their closet neighbors while normal instances are located in dense neighbors.
- Methods
- REPEN: Random neighbor distance-based: The representations are optimized so that the nearest neighbor distance of pseudo-labeled anomalies in random subsamples is substantially larger than that of pseudo-labeled normal instances. The pseudo labels are generated by some off-the-shelf anomaly detectors. The loss function is built upon the hinge loss.
- RDP: The other uses the distance between optimized representations and randomly projected representations of the same instances to guide the representation learning. Solving
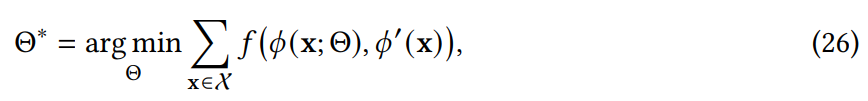 is equivalent to have a knowledge distillation from a random NNs and helps learn the frequency of different underlying patterns in the data.
is equivalent to have a knowledge distillation from a random NNs and helps learn the frequency of different underlying patterns in the data. - At the evaluation stage, the function of \(f\) is used to compute the anomaly score.
- Advantages
- The distance-based anomalies are straightforward and well defined with rich theoretical supports in the literature.
- They work in low-dimensional representation spaces and can effectively deal with high-dimensional data that traditional distance-based anomaly measures fail.
- They are able to learn representations specifically tailored for themselves.
- Disadvantages
- The extensive computation involved in most of distance-based anomaly measures
- Their capabilities may be limited by the inherent weaknesses of the distance-based anomaly measures.
- Challenges
- CH1&CH2
- CH3,CH4
One-class classification measure
Aims to learn feature representations customized to subsequent one-class classification-based anomaly detection. Learn a description of a set of data instances to detect whether new instances conform to the training data or not.
One way is to learn representations that are specifically optimized for these traditional one-class classification models, like one-class SVM.
Assumption: all normal instances come from a single class and can be summarized by a compact model, to which anomalies do not conform.
Methods
AE-1SVM, OC_NN: Deep one-class SVM, learn the one-class hyperplane from the neural network-enabled low-dimensional representation space rather than the original input space.
The formula is
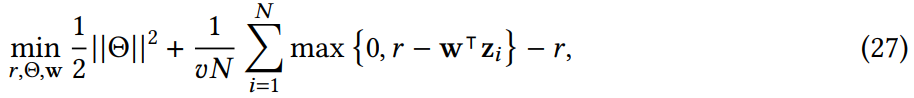 Any instances that have $𝑟 − ^_𝑖 $ can be reported as anomalies. It has two benefits:
Any instances that have $𝑟 − ^_𝑖 $ can be reported as anomalies. It has two benefits:- It can leverage deep networks to learn more expressive features for downstream anomaly detection
- It can also help remove the computational expensive pairwise distance computation in the kernel functions.
- Based on one-class SVM, one may use a random mapping to map latent representation \(\mathrm{z}\) to Fourier features since many kernel functions can be approximated by random Fourier features.
Deep SVDD, Deep SAD: Another way is deep models for SVDD, which aims at Learning a minimum hyperplane characterized by a center \(\mathrm{c}\) and a radius \(r\) so that the sphere contains all training data instances.

It's shown that \(\mathrm{c}\) as trainable parameters can lead to trivial solutions. \(\mathrm{c}\) can be fixed as the mean of the feature representations yield by performing a single initial forward pass. The key idea is to minimize the distance of labeled normal instances to the center while at the same time maximizing the distance of known anomalies to the center.
Advantages
- The one-class classification-based anomalies are well studied in the literature and provides a strong foundation of deep one-class classification-based methods.
- The representation learning and one-class classification models can be unified to learn tailored and more optimal representations.
- They free the users from manually choosing suitable kernel functions in traditional one-class model.
Disadvantages
- The one-class models may work ineffectively in datasets with complex distributions within the normal class.
- The detection performance is dependent on the one-class classification-based anomaly measure.
Challenges : CH1&CH2, CH3
Clustering-based measure
Aims at learning representations so that anomalies are clearly deviated from the clusters in the newly learned representation space.
Methods use like cluster size, distance to cluster centers, distance between cluster centers, and cluster membership to define clusters.
Assumptions: Normal instances have stronger adherence to clusters than anomalies.
Many methods are explored based on the motivation that the performance of clustering methods is highly dependent on the input data.
The deep clustering methods typically consist of two modules: performing clustering in the forward pass and learning representations using the cluster assignment as pseudo class labels in the backward pass.
The clustering loss can be initialized with a kmeans loss, a spectral clustering loss, an agglomerative loss or a GMM loss.
The auxiliary loss can be an autoencoder-based reconstruction loss to learn robust and/or local structure preserved representations.
The cluster assignments in the resulting function is used to compute anomaly scores.
The aforementioned deep clustering methods are focused on learning optimal clustering results, but the learned representations may not be able to well capture the abnormality of anomalies. Papers
- The cluster loss is GMM loss and the auxiliary loss is autoencoder-based reconstruction loss.
- The auxiliary loss is an an autoencoder-based reconstruction loss, but to learn deviated representations of anomalies.
Advantages
- A number of deep clustering methods and theories can be utilized to support the effectiveness and theoretical foundation of anomaly detection.
- Learn specifically optimized representations that help spot the anomalies easier than on the original data, especially when dealing with intricate data sets.
Disadvantages
- The performance of anomaly detection is heavily dependent on the clustering results.
- The clustering process may be biased by contaminated anomalies in the training data, which in turn leads to less effective representations.
Challenges: CH1&CH2, CH4
End-to-end anomaly score learning
Aims at learning scalar anomaly scores in an end-to-end fashion. It has a NN that directly learns the anomaly scores. Methods here won't be limited by the inherent disadvantages of the incorporated anomaly measures. There are two design directions: one focuses on how to synthesize existing anomaly measures and neural network models, while another focuses on devising novel loss functions for direct anomaly score learning.
Ranking models
Aims to directly learn a ranking model, such that data instances can be sorted based on an observable ordinal variable associated with the absolute/relative ordering relation of the abnormality.
Assumptions: There exists an observable ordinal variable that captures some data abnormality.
Methods
One line is to devise ordinal regression -based loss functions to drive the anomaly scoring neural network.
- Two-class ordinal regression.
- The end-to-end anomaly scoring network takes \(\mathcal{A}\) and \(\mathcal{N}\) as inputs and learns to optimize the anomaly scores such that the data inputs of similar behaviors as those in \(\mathcal{A(N)}\) receive large (small) scores as close \(𝑐_1 (𝑐_2)\) as possible, resulting in larger anomaly scores assigned to anomalous frames than normal frames.
- Two-class ordinal regression.
Weakly-supervision
MIL: the model is optimized to learn larger anomaly scores for the pairs of two anomalies than the pairs with one anomaly or none.
MIL ranking model, directly learn the anomaly score for each video segment. Its key objective is to guarantee that the maximum anomaly score for the segments in a video that contains anomalies somewhere is greater than the counterparts in a normal video.
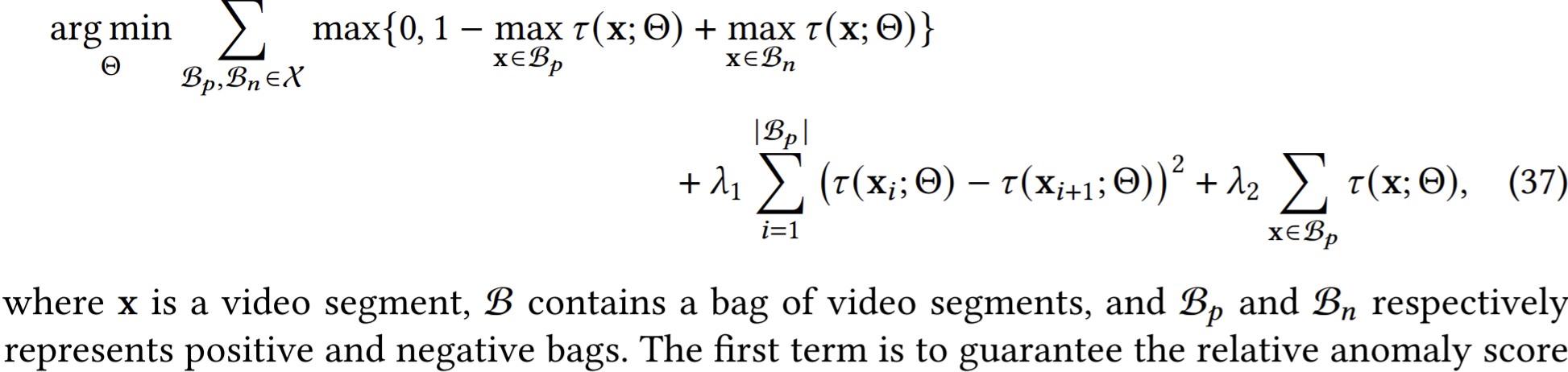
- Why not \(\min\) at the last term in the 1st term?
- The first term is to guarantee the relative anomaly score order, i.e., the anomaly score of the most abnormal video segment in the positive instance bag is greater than that in the negative instance bag. The last two terms are extra optimization constraints, in which the former enforces score smoothness between consecutive video segments while the latter enforces anomaly sparsity, i.e., each video contains only a few abnormal segments.
Advantages:
- The anomaly scores can be optimized directly with adapted loss functions.
- They are generally free from the definitions of anomalies by imposing a weak assumption of the ordinal order between anomaly and normal instances.
- This approach may build upon well-established ranking techniques and theories from areas like learning to rank.
Disadvantages
- At least some form of labeled anomalies are required.
- Methods may not be able to generalize to unseen anomalies cause they are designed to detect labeled anomalies.
Challenges:
- CH1&CH2;
- CH3
- CH6
- CH4
Prior-driven models
Use a prior distribution to encode and drive the anomaly score learning. The prior may be imposed on either the internal module or the learning output of the score learning function.
Assumptions: The imposed prior captures the underlying (ab)normality of the dataset.
Methods
DevNet: enforce a prior on the anomaly scores. It uses a Gaussian prior to encode the anomaly scores and enable the direct optimization very well. The deviation loss is built upon contrastive loss.

- Driven by the deviation loss, it will push the anomaly scores of normal instances as close as possible to 𝜇 while guaranteeing at least 𝑚 standard deviations between 𝜇 and the anomaly scores of anomalies.
- The loss is equivalent to enforcing a statistically significant deviation of the anomaly score of the anomalies from that of normal instances in the upper tail.
- It's also interpretable.
Advantages
- The anomaly scores can be directly optimized w.r.t. a given prior.
- It provides a flexible framework for incorporating different prior distributions into the anomaly score learning.
- The prior can also result in more interpretable anomaly scores than the other methods.
Disadvantages
- It's difficult to design a universally effective prior for all anomaly detection application.
- The efficiency of model depends on how the picked prior fits the underlying distribution.
Challenges
- CH1&CH2
- CH1&CH3
- CH4
Softmax Likelihood models
Learning anomaly scores by maximizing the likelihood of events in the training data. Normal instances are presumed to be high-probability events whereas anomalies are prone to be low-probability events. Tools like NCE are used.
- Assumptions: Anomalies and normal instances are respectively low- and high-probability events.
- Methods
- Use log negative likelihood. Learning the likelihood function 𝑝 is equivalent to directly optimizing the anomaly scoring function.
- But the original likelihood is computed costly, NCE is used to alleviate. For each instance \(\mathrm{x}\), \(k\) noise samples \(\mathrm{x}_{1, \cdots,k}\sim Q\) are generated from some synthetic known ‘noise’ distribution \(Q\).
- Advantages
- Different types of interactions can be incorporated into the anomaly score learning process.
- The anomaly scores are faithfully optimized w.r.t. the specific abnormal interactions we aim to capture.
- Disadvantages
- The computation of the interactions can be very costly when the number of features/elements in each data instance is large.
- The anomaly score learning is heavily dependent on the quality of the generation of negative samples.
- Challenges
- CH2&CH5
- CH1
End-to-end one-class classification
Train a one-class classifier that learns to discriminate whether a given instance is normal or not. It does not rely on any existing one-class classification measures. Methods like adversarially learned one-class classification are used. It learns a one-class discriminator of the normal instances so that it well discriminates those instances from adversarially generated pseudo anomalies. The goal is to learn a discriminator and this discriminatory will be directly used as anomaly scorer.
Assumptions :
- Data instances that are approximated to anomalies can be effectively synthesized.
- All normal instances can be summarized by a discriminative one-class model.
Methods
-
- The key idea is to train two deep networks, with one network trained as the one-class model to separate normal instances from anomalies while the other network trained to enhance the normal instances and generate distorted outlier. The generator is based on a denoising AE.
- The outliers are randomly sampled from some classes other than the classes where the normal instances come from.
- But this method may be unavailable in many domains cause the reference outliers are beyond the given data.
OCAN, FenceGAN: generate fringe data instances based on the given training data and use them as negative reference instances to enable the training of the one-class discriminator.
OCAN: The generator is trained to generate data instances that are complementary to the training data.
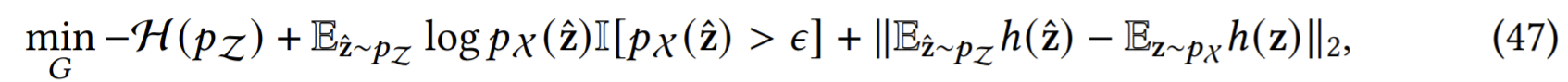
The 1st two terms are devised to generate low-density instances in the original feature space, and the last term is to help better generate data instances within the original data space.
The objective of the discriminatory is enhanced with an extrovert conditional entropy loss to enable the detection with high confidence.
FenceGAN: generate data instances tightly lying at the boundary of the distribution of the training data, which is achieved by introducing two loss functions into the generator that enforce the generated instances to be evenly distributed along a sphere boundary of the training data.
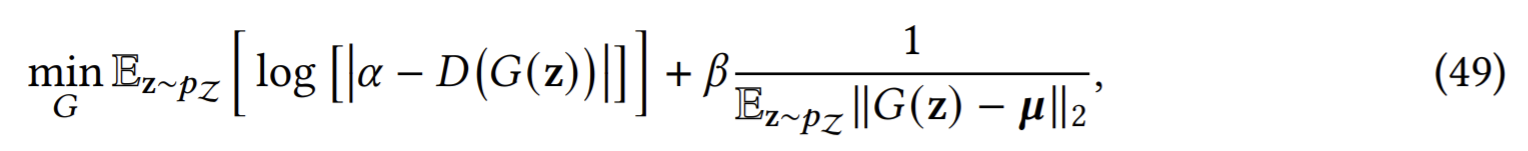
The first term is called encirclement loss that enforces the generated instances to have the same discrimination score, ideally resulting in instances tightly enclosing the training data. The second term is called dispersion loss that enforces the generated instances to evenly cover the whole boundary.
OCGAN: uniformly distributed instances can be generated to enforce the normal instances to be distributed uniformly across the latent space.
An ensemble of generator is used with each generator synthesizing boundary instances for one specific cluster of normal instances.
-
Advantages
- Its anomaly classification model is adversarially optimized in an end-to-end fashion.
- It can be developed and supported by the affluent techniques and theories of adversarial learning and one-class classification.
Disadvantages
- It is difficult to guarantee that the generated reference instances well resemble the unknown anomalies.
- The instability of GANs may lead to generated instances with diverse quality and consequently unstable anomaly classification performance.
- Its applications are limited to semi-supervised anomaly detection scenarios.
Challenges
- CH1 & CH2
Algorithms and datasets
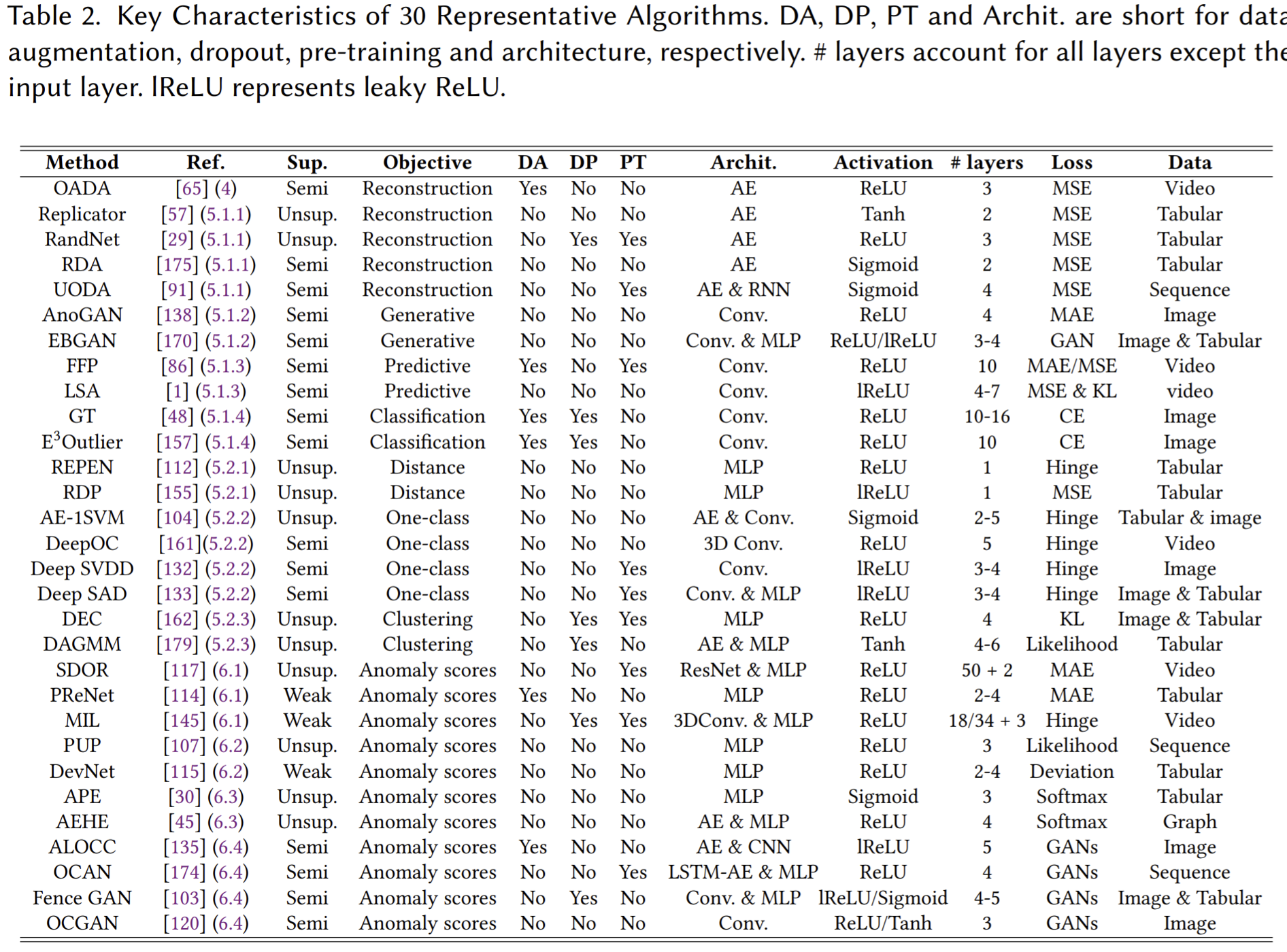
Representative algorithms
Most methods operate in an unsupervised or semi-supervised mode.
Deep learning tricks like data augmentation, dropout and pre-training are under-explored.
The network architecture used is not that deep.
(leaky) ReLU is the most popular one
diverse backbone networks can be used to handle different types of input data.
Datasets with Real anomalies

Conclusion
- Contributions
- Problem nature and challenges: some unique problem complexities underlying anomaly detection and the resulting largely unsolved challenges.
- Categorization and formulation: three principled frameworks: deep learning for generic feature extraction, learning representations of normality, and end-to-end anomaly score learning
- Comprehensive literature review
- Future opportunities
- Source codes and datasets
- Exploring anomaly-supervisory signals
- The key issue for these formulations is that their objective functions are generic.
- Explore new sources of anomaly-supervisory signals that lie beyond the widely-used formulations such as data reconstruction and GANs, and have weak assumptions on the anomaly distribution.
- Develop domain-driven anomaly detection by leveraging domain knowledge.
- Deep weakly-supervised anomaly detection
- Leveraging deep neural networks to learn anomaly-informed detection models with some weakly-supervised anomaly signals.
- Utilize a small number of accurate labeled anomaly examples to enhance detection models.
- Unknown anomaly detection: aim to build detection models that are generated from the limited labeled anomalies to unknown anomalies.
- Data-efficient anomaly detection or few-shot anomaly detection: given only limited anomaly examples.
- Leveraging deep neural networks to learn anomaly-informed detection models with some weakly-supervised anomaly signals.
- Large scale normality leaning
- Since it is difficult to obtain sufficient labeled data
- The goal is to first learn transferable pre-trained representation models from large-scale unlabeled data in an unsupervised/self-supervised mode, and then fine-tune detection models in a semi-supervised mode.
- May need to be domain/application-specific.
- Deep detection of complex anomalies
- conditional/group anomalies
- Multimodal anomaly detection
- Interpretable and actionable deep anomaly detection
- The abnormal feature selection methods but may render the explanation less useful
- Novel applications and settings
- Out-of-distribution detection: closely related area. It is generally assumed that fine-grained normal class labels are available during training.
- Curiosity learning: learning a bonus reward function in reinforcement learning with sparse rewards. Augmenting the environment with a bonus reward in addition to the original sparse rewards from the environment.
- non-IID anomaly detection: e.g., the abnormality of different instances/features is interdependent and/or heterogeneous. May be confused with anomaly instances.
- detection of adversarial examples, anti-spoofing in biometric systems, and early detection of rare catastrophic events.
Project II: Graph Level Anomaly Detection
Why?
Anomaly detection at a graph level rather than node level or links level.
Goals
modeling a comprehensive representation of a graph’s local and high level structural features, as well as a challenging problem because of the unique properties of graph based data, such as long dependencies and size variability.
Previous
- You et al. propose an autoregressive approach to graph generation that is trained sequentially on existing graphs and then generates them at inference time by breaking the process into a sequence of node and edge formations
- You et al.’s work in an RL approach to goal-directed molecular graph generation. Using partially observed subgraphs (discussed later) and an action-based generation framework v
How?
Idea
Formulate two unsupervised learning objectives for graph level anomaly detection. Namely, we compare 1) generative modeling for graph likelihood estimation and 2) a novel method based on masked graph representation learning.
look to learn meaningful representations over a family of graphs by modeling one step edge completion problems.