- Fall detection
- Paper I: Elderly Fall Detection Systems: A Literature Survey, 2020
- Paper II: A survey on vision-based fall detection, 2015
- Paper III: 3D depth image analysis for indoor fall detection of elderly people, 2015
- Paper IV: Deep learning based systems developed for fall detection: a review, 2020
- Paper V: Implementation of Fall Detection System Based on 3D Skeleton for Deep Learning Technique, 2019
- Paper VI: Human fall-down event detection based on 2D skeletons and deep learning approach
- Human activity recognition
- Paper VII: Vision-based human activity recognition: a survey, 2020
- 3D and depth data
- 3D skeleton-based human representations
- knowledge-based HAR activity recognition
- Abnormal HAR
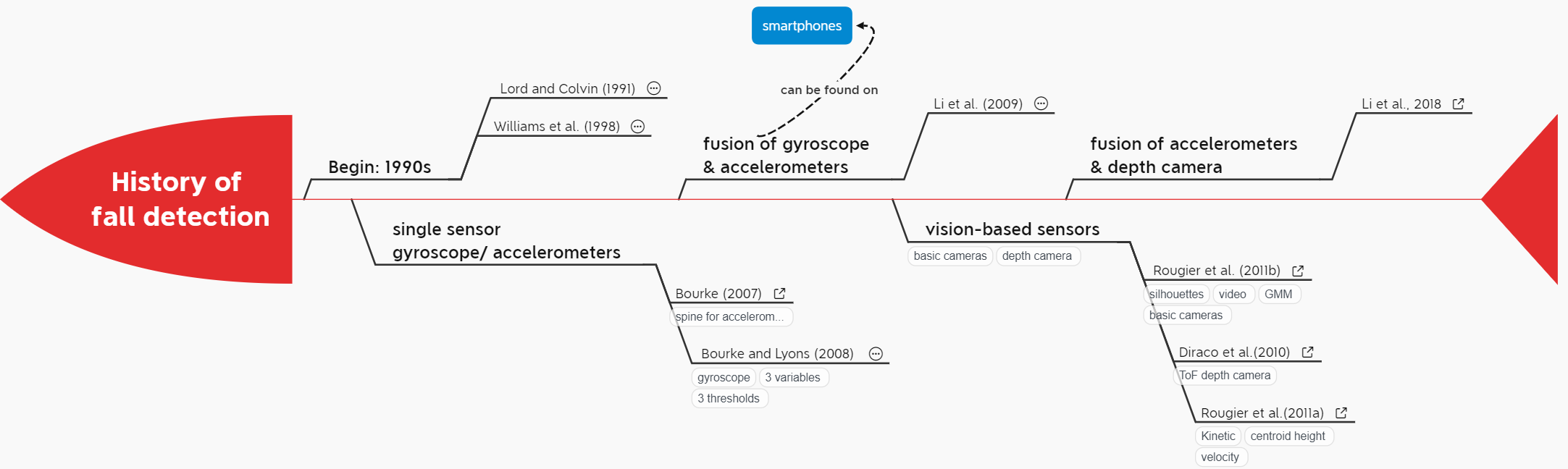
Fall detection
Paper I: 2020
Elderly Fall Detection Systems: A Literature Survey, 2020
Why?
Types of falls
- Types
- forward, lateral and backward in El-Bendary et al.
- forward, backward, left-side, right-side, blinded-forward and blinded-backward in Putra et al.
- fall lateral left lie on the floor, fall lateral left and sit up from floor, fall lateral right and lie on the floor, fall lateral and left sit up from the floor, fall forward and lie on the floor, and fall backward and lie on the floor in Chen et al
- Elderly people may suffer from longer duration of falls, because of motion with low speed in the activity of daily living
- The characteristics of different types of falls are not taken into consideration in most of the work on fall detection surveyed. (like age, gender etc.)
Previous work and falls
| Paper | contents | summary |
|---|---|---|
| Chaudhuri et al. (2014) | fall detection devices for people of different ages (excluding children) from several perspectives, including background, objectives, data sources, eligibility criteria, and intervention methods. | most of the studies were based on synthetic data |
| Zhang et al. (2015) | vision-based fall detection systems and their related benchmark data sets. Methods are divided into four categories, namely individual single RGB cameras, infrared cameras, depth cameras, and 3D-based methods using camera arrays. Methods are also divided to rely on the activity/inactivity of the subjects, shape (width-to-height ratio), and motion. | Non-vision sensors are not included |
| Cai et al. (2017) | depth cameras, reviewed the benchmark data sets acquired by Microsoft Kinect and similar cameras. | helpful for looking for benchmark data sets |
| Chen et al. (2017a) | vision- and non-vision-based systems | fusion of depth cameras and inertial sensor resulted in a system that is more robust |
| Igual et al. (2013) | low-cost cameras and accelerometers embedded in smartphones may offer the most sensible technological choice for the investigation of fall detection. They also reported three main challenges: (i) real-world deployment performance, (ii) usability, and (iii) acceptance. | another option of sensors |
Goals
provide a literature survey of work conducted on elderly fall detection using sensor networks and IoT in terms of data acquisition, data analysis, data transport and storage, sensor networks and Internet of Things (IoT) platforms, as well as security and privacy.
How?
The components of system
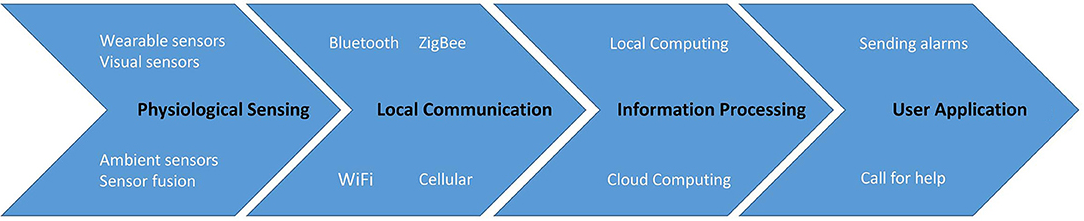
Sensors
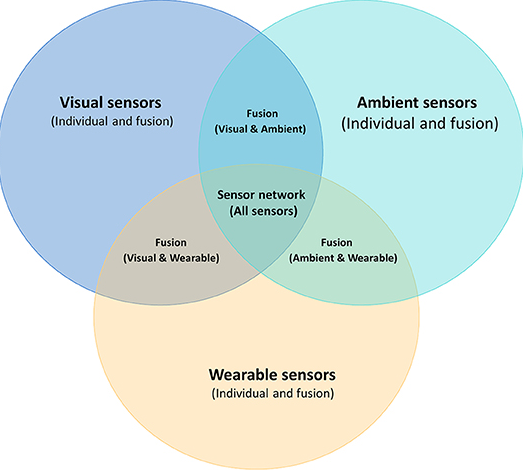
- Individual wearable sensors
- possible choices: accelerometers, gyroscopes, glucometers, pressure sensors, ECG (Electrocardiography), EEG (Electroencephalography), or EOG (Electromyography)
- Bourke et al. (2007) found that accelerometers are regarded as the most popular sensors for fall detection. Smart phones are more practical compared with wearable sensors.
- Individual vision sensors
- Possible choices: infrared, RGB, RGB-D etc.
- main challenge of vision-based detection is the potential violation of privacy
- Almost use synthetic falling dataset. Boulard et al. (2014) has actual fall data and the other by Stone and Skubic (2015) has mixed data.
- Individual ambient sensors
- Possible choices: active infrared RFID,pressure, smart tiles, magnetic switches, doppler radar, ultrasonic and microphone.
- Subjects
- simulated data from OpenSim contributed to an increase in performance to the resulting models
- transfer learning which adapt to subjects who were not represented in the training data
- reinforcement learning for different subjects
Sensor fusion
Types
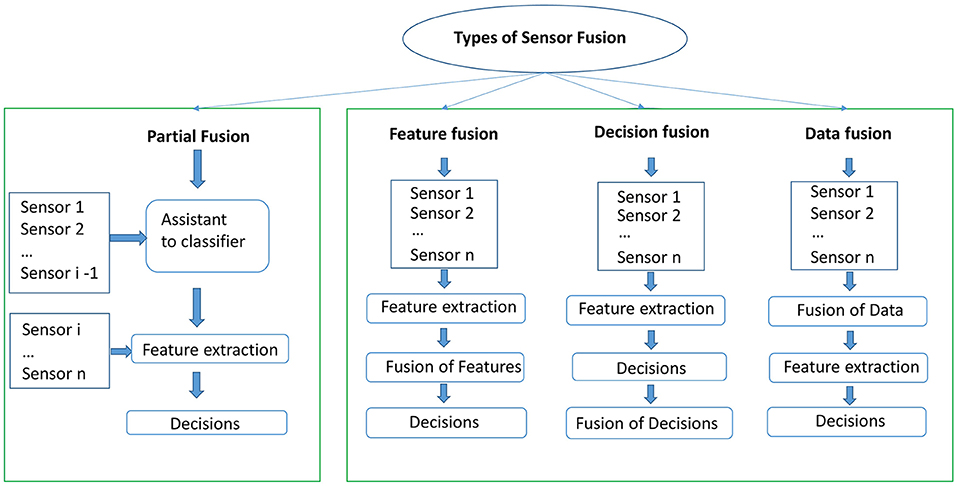
feature fusion is the most popular approach, followed by decision fusion.
Trends & challenges
Trends
- Sensor fusion
- ML,DL and RL
- With 5G wireless networks
- Data augmentation
- Personalized data: the historical medical and behavioral data of Individuals (El-Bendary et al. (2013) and Namba and Yamada (2018b))
- Use skeletal models for simulation: Mastorakis et al. (2007, 2018), applied the skeletal model simulated in Opensim,
- Fog computing : Intel RealSense includes a 28 nanometer processor
Challenges
- The rarity of data of real falls : only Liu et al. (2014) used a data set with nine real falls along with 445 simulated ones.
- Detection in real-time
- Security and privacy
- Platform of sensor fusion
- Limitation of locations: indoor and outdoor environments
- Scalability and flexibility
Paper II: vision
A survey on vision-based fall detection, 2015
Goal
focus on recent vision-based fall detection techniques, including depth-based methods;
discuss the publicly available fall datasets.
Fall datasets
[1] Definition and performance evaluation of a robust svm based fall detection solution.
[2] Multiple cameras fall dataset
The EDF dataset mentioned in this paper, I cannot find the original paper except for this one , in which EDF and OCCU are both created. But if it's the paper I list, the description of EDF in this paper is not totally correct.
| - | SDUFall | EDF? | OCCU | [1] | [2] |
|---|---|---|---|---|---|
| camera type | 1 kinetic | 2 kinetics | 2 kinetics | 1 RGB camera | 8 calibrated RGB camera |
| camera viewpoints | 1 | 2 | 2 | NaN | 8 |
| fall type | falls with different directions | eight fall directions | occluded falls | falls with different directions | forward, backward falls, falls from sitting down and loss of balance |
| #falls | 200 | 320 | 60 | 192 | 200 |
| actions in daily life? | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) | \(\checkmark\) |
| #scenarios | 1 | 1 | 1 | 4 (home, coffee room, office, lecture room) | 24 |
| #subjects | 20 | 10 | 5 | 1 | |
| resolution | \(320\times240\) | \(320\times240\) | \(320\times240\) | ||
| frame rate | 30 fps | 25 fps | 30 fps | 25 fps | |
| year | 2014 | 2008 | 2014 | 2012 | 2010 |
Vision-based fall detectors
1 | Comment: the classification rules for each section are not the same. |
Using single RGB camera
Firstly classify by features, then the tasks of it is mentioned
- Shape-related features : based on width to height aspect ratio of the person.
- background separation to get silhouette and then use SVM for classification:
- shape deformation from silhouettes and use shape deformation based GMM for classification
- ellipse shape for body modeling and GMM for extracting moving object.
- 2 HMMs for classify falls and normal activities
- extracting projection histograms of the segmented body silhouette and then use it as feature vector, complete posture classification by KNN.
- Motion pattern
- human motion analysis (analyzing the energy of the motion active area ) + human silhouette shape variations to detect slip-only and fall events
- applying Integrated Time Motion Image (ITMI) to fall detection. ITMI is the calculated the PCs of typical video clip for representing a motion pattern.
- threshold-based by the last few frames (falling, the magnitude of the fall, the maximum velocity of the fall ) etc.
- extract the 3D head trajectory using a single calibrated camera.
- extract foreground human silhouette via background modeling. Ellipse fitting for human body and analyze silhouette motion by an integrated normalized motion energy image.
- Inactivity detection
- use ceiling-mounted, wide-angle cameras with vertically oriented optical axes to reduce the influences of occlusion.
- use learned models of spatial context in conjunction with a tracker
- STHF descriptor by Charfi et al.
Using multiple cameras
Classified by tasks
- 3D reconstruction
- volume distribution along the vertical axis, check here.
- multiple cameras + a hierarchy of fuzzy logic to detect falls. Use voxel person (linguistic summarization of temporal fuzzy inference curves)
- Multiple viewpoint
- Use LHMM (layered hidden Markov model)
- combining decisions from different camera
- Using the measures of humans heights and occupied areas.
Using depth cameras
- Using the distance from the top of the person to the floor
- the distance of human centroid to floor is smaller than threshold and the person does not move for a certain seconds
- Other features like head to floor distance, person area and shape's major length to width
- analyzing how a human has moved during the last frames
- characterize the vertical state of a segmented 3D object for each frame. Then compute a confidence by the features extracted on ground event which are fed into an ensemble of decision trees.
- Bayes network on fall detection, including duration, total head drop, maximum speed, smallest head height and fraction of frames for which the head drops
- calculating the velocity based on the contraction or expansion of the width, height and depth of the 3D bounding box.
- human body key joints
- 3D body joints at each frame are extracted by randomized decision tree, and the 3D trajectory of the head joint is used to determine whether the fall action has occurred.
- 3D depth for main detection (structure similarity and vertical height of the person), RGB for out-of-the-rage of the depth camera (the width-height ratio of the detected human bounding box is for recognizing different activities).
- an action is represented by a bag of curvature scale space features (BoCSS) of human silhouettes. Or represent an action as Fisher Vector (on CSS). Or check whether the width-height ratio of temporal bounding box is greater than the predefined threshold, if it is, then it's fall. Otherwise check 2D velocity and the 3D centroid information
Conclusions
Methods with cameras
method merits demerits single RGB camera * no requirement of camera calibration
* inexpensive* case specific and viewpoint-dependent
* occlusion problemcalibrated multi-camera systems * viewpoint independent
* No occlusion* careful and time-consuming calibration
* repeatedly calibration if any of them moveddepth camera * viewpoint independent
* No occlusion* price Tips for benchmark
- both falls and activities of daily life (ADL) are requried
- include various falls
- include different camera viewpoints: to verify whether the proposed algorithms are viewpoint-independent
- real falls: consider the distribution of volunteers like gender, ages etc.
Tips for fall detection
- combine with Other type of data like sound,
Paper III: 3D depth
3D depth image analysis for indoor fall detection of elderly people, 2015
Previous
Existing fall detection methods
wearable sensor based
small , cheap, wearable, but high drift
ambient sensor-based
low detection precision of these sensors, and the precision is distance-relied and thus more sensors are required if with a bigger room
computer-vision based
more robust and less intrusive.
- methods with a single RGB camera
- 3d-based methods Using multiple cameras
- depth camera
Usually shape relative features of human motion analysis and inactivity detection are used as clues for detecting falls.
moment functions are powerful while describing the human shape
- On grey or color images an ellipse is more accurate than a bounding box
- depth camera can offer 3D data so as to work on shape analysis
Threshold based fall detection
- Features that can be used: head-ground distance gap and head-shoulder distance gap, the orientation of the ellipse of the human object and the motion of the human object
- methods: DT, NNs, SVM, Bayesian Belief Network
Goal
deals with the fall detection of the single elderly person in the home environments
How?
Idea
- extracting silhouette of moving Individual by extracting background frame
- with the horizontal and vertical projection histogram statistics the depth images are converted to disparity map
- coefficients of the human body are calculated to determine the direction of individual
- threshold based: centroids of the human body to the floor plane and the angle between the human body and the floor plane
Method

Data preprocessing
depth data: only adopt kinetic data in trusted range (1.2-3.8m)
extracting silhouette of the moving individual: subtracting the median-filtered background depth frame
floor plane: disparity map. Floor plane will be a noticeable slant and thick straight line in the disparity map
$= $, for kinetic, \(f=580\) pixels, \(b=7.5\) cm, and \(d\) is the distance between one point in the space TPM the center of the kinetic.

The floor equation then is
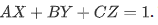
The orientation of human body: after estimating the ellipse of human body on the image plane, then estimate orientation
calculate the distance from the centroid of the human body to the floor plane and the angles between the body and the floor plane.

Experiments
- The dataset is based on their self-captured dataset.-- Cannot find the sharing link of dataset
- Only two clips' trajectories are listed, no accuracy data shown
Conclusions
- the method may be taken as a candidate
- the result of experiments is not convince.
Paper IV: DL
Deep learning based systems developed for fall detection: a review, 2020
Previous
- the reviewed fall detection systems have some general steps, combined with sensing, data processing, fall event recognition and emergency alert system to rescue the victim.
Goal
presenting a summary and comparison of existing state-of-the-art deep learning based fall detection systems to facilitate future development in this field.
The categorization focuses on how the different principal methods (CNN, LSTM, and AE) handle the event data captured by sensors.
How?
Methods used for fall detection
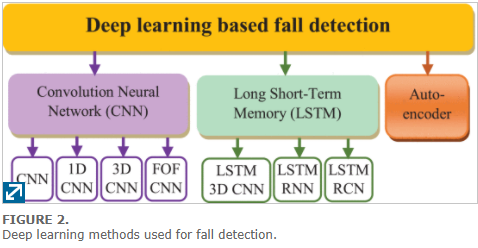
CNN based fall detection systems
CNN
- Adhikari et al : based on videos images from RGB-D camera .
- used their own dataset
- poor sensitivity when the user was in crawling, bending and sitting positions. The system also works in a selected environment. Developed on a single-person scenario
- Li et al: extract human shape deformation by CNNs
- used dataset URFD
- not tested on real dataset
- Yhdego et al.:
- convert the data from accelerometer to image by continuous wavelet transform
- use transfer learning for these images
- use URFD dataset
- Yu et al
- extract human body silhouette by background subtraction. CNN is for preprocessing the silhouette
- codebook background subtraction
- Shen et al.
- cloud
- deep-cut NNs to detect the key points of human body, feed key points into NNs
- Santos et al
- IoT, fog computing
- used three open datasets
- Zhou et al : multi-sensor fusion
- STFT is for extracting the time frequency (TF) micro-motion features
- Two Alexnet and one SSD (single shot multi-box detector) net are for classifying the TF features
- He et al.: FD-CNN net
- collected data is mapped into 3-channel RGB bitmap image
- the image plus SisFall and MobiFall datasets for training FD-CNN
- Sadreazami et al : CNN for time-series data (radar)
- Sortis et al : raw accelerometer data, CUSUM (cumulative sum) algorithm
- Lu et al: use optical flow images, pretrained 3D CNN on different dataset, transfer learning. Accurate for single-person detection but may not work well on multi-person detection
- Wang et al: tri-axial accelerometer, gyroscope sensor in the smart insole. CNN for improving the accuracy level (it's used directly on the raw sensor data)
- Zhang and Zhu: CNN that works on raw 3-axis accelerometer data streams.
- Camerio et al: multi-stream model, takes high-level handcrafted feature generators. CNN for optical flow, RGB and human estimated pose. Use URFD and FDD datasets for training
- Casilari et al :CNN for recognizing the pattern from the tri-axial transportable accelerometer. Using multiple dataset for training. For real-life performance, LSTM is used
- Espinosa et al : Using UP-fall detection multi-modal dataset. Only vision-based .
1D CNN
- Cho and Yoon : SVD on accelerometer data for 1Data CNN. Works for triaxial acceleration data.
- Tsai and Hsu et al.: feature extraction algorithm for converting the depth image to skeleton information . Only seven highlighted feature points are picked from the skeleton joints. Performs well on NTU RGB+D
3D CNN
- Ranhnemoonfar et al.: Kinect depth camera, Adam optimizer. SDUFall dataset for training.
- Li et al.: pre-impact fall detection. Pretrained model + new samples for fine tuning.
- Hwang et al.: 3D-CNN for continuous motion data from depth cameras. Using data augmentation. Using TST fall detection dataset
- Kasturi et al.: kinetic camera. the data fed into 3DCNN is a staked cube. Tested on UR fall detection dataset
FOF CNN
FOF: feedback optical flow convolution
- Hsieh and Jeng : IoT, used Feature Feedback Mechanism Scheme (FFMS) and 3D-CNN. KTH dataset.
LSTM based fall detection systems
LSTM with 3D CNN
- Lu et al.: trained an extractor only on kinetic data, LSTM+ spatial visual attention. Use Sports-1M dataset, and fall dataset of Multiple Cameras.
LSTM with RNN and CNN
- Lie et al.: CNN for extracting 2D skeletons from RGB camera, LSTM for classifying actions. Has an online version
- Abobakr et al.: Kinect RGB-D camera. Convolutional LSTM + ResNet for visual feature extraction, LSTM for sequence modeling and logistics regression for fall detection. Use URFD public dataset, can work in real-time
- Xu et al.: IoT, acceleration data from a tri-axial accelerometer as input . Outperfoms SVM+CNN model,
- Tao and Yun: body posture and human biomechanics equilibrium, fed depth camera data to RNN+LSTM and extracting 3D skeletons. Then by computing center of mass (COM) positions and the region of base support, falls are detected.
- Ajerla et al. : used edge devices like a laptop for computing, MetaMotionR sensor (tri-axial accelerometer), subset of the MobiAct public dataset for training,
- Queralta et al.: edge computing and fog computing. LSTM+RNN
- Luna-Perejon et al.: LSTM+GRU, accelerometer data as input, SisFall dataset for training.
- Torti et al.: Micro-Controller Unit (MCU) with Tri-axial accelerometers, LSTM, tensorflow, SisFall dataset
- Theodoridis et al. : acceleration measurements, RNN, URFD dataset + random 3D rotation augmentation for training. Comparing 4 type of model: LSTM-Acc, LSTM-Acc Rot, Acc + SVM-Depth, UFT
- Hsiu-Yu et al. : kinetics, posture Types, LSTM compared with CNN, fusion images as input from RGB images after extracting body shape by GMM and optical flow.
LSTM with RCN and RNN
- Ge et al.: kinect, co-saliency-enhanced RCN, input video clips, RCN + (RNN+LSTM) to label the output.
AE based fall detection systems

- Jokanovic et al.: time-frequency (TF) analysis. two stacked AE and a softmax layer.
- Droghini et al.: acoustic fall detection, DT (downstream threshold) classifier.
- Zhou and Komuro et al.: VAE+3D-CNN residual block, reconstruction error for detecting fall actions. Dataset High-quality simulated fall dataset (HQFD) and Le2i dataset.
- Seyfioglu et al.: 3 layer-CAE. unsupervised pretraining for the convolutional layers, radar
Conclusion
- Sensors:
- RGB camera: not privacy and thus cannot be used in bathroom which with highly risk. Hacker
- Depth camera: only depth, but can be used in like bathroom
- Accelerator: cheap and the data captured are easy to be used,
- Vision based methods really depend on the background
Paper V: 3D skeletons
Implementation of Fall Detection System Based on 3D Skeleton for Deep Learning Technique
Previous
- Kinect: depth sensor + RGB camera + microphone array
- silhouette normalization : sensitive to the background
- high computation price
Goal
real-time fall detection
Idea
Methods: seven highlight feature points+ pruned CNNs
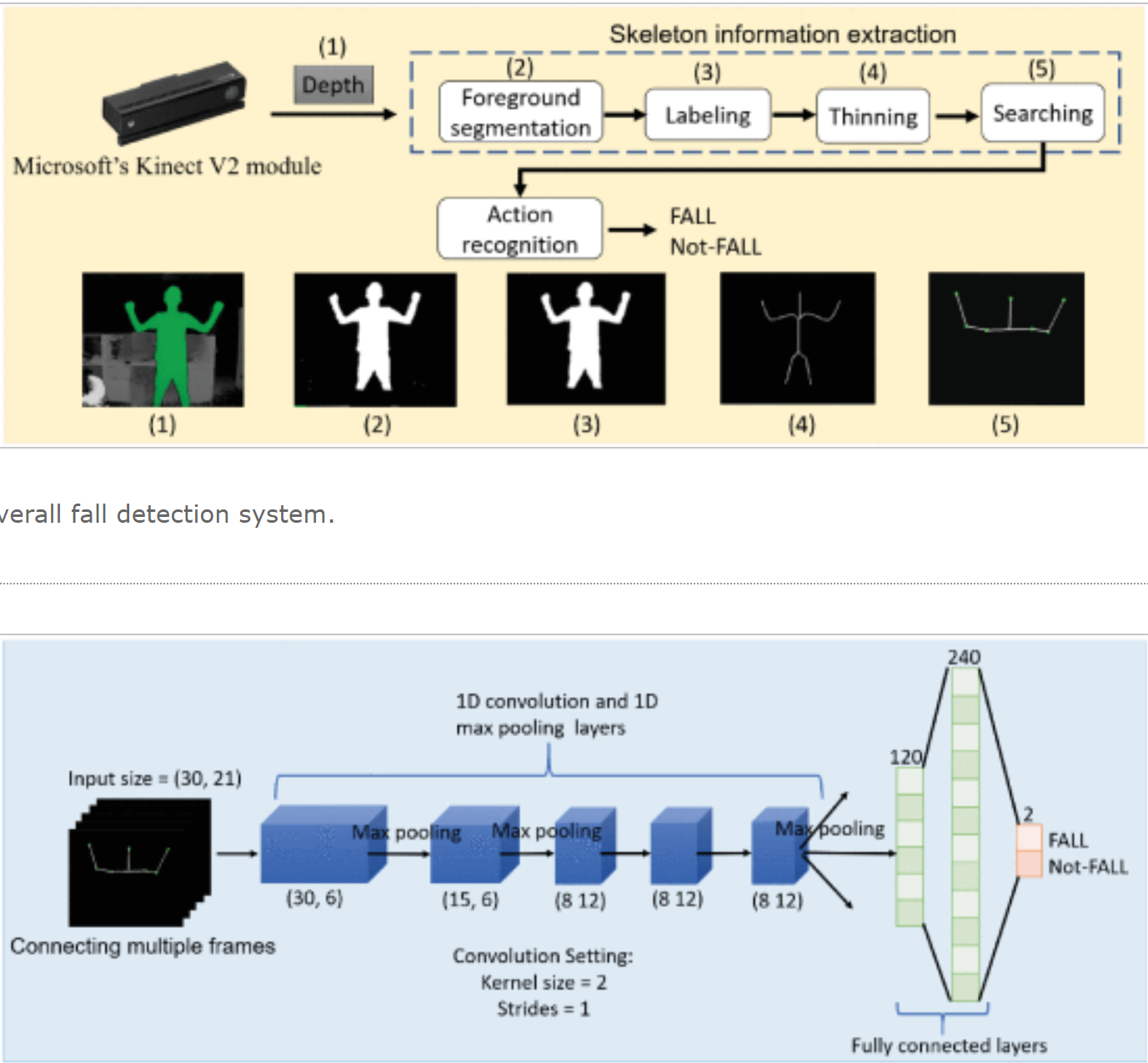
- Foreground segmentation: GMM, depth information
- Labeling: use the area size to determine whether the object is human or not.
- Thinning: Use Zhang Suen's rapid thinning method. Dilation + erosion
- Searching: just Using the joints on arms and head, they argue that when a falling event will occur, the joints above the waist will have enormous change.
Input: 7 3D joints in 30 frames, (30,21).Use conv1d (so as to prune the number of parameters)
Experiments
Dataset: NTU RGB+D
Performance
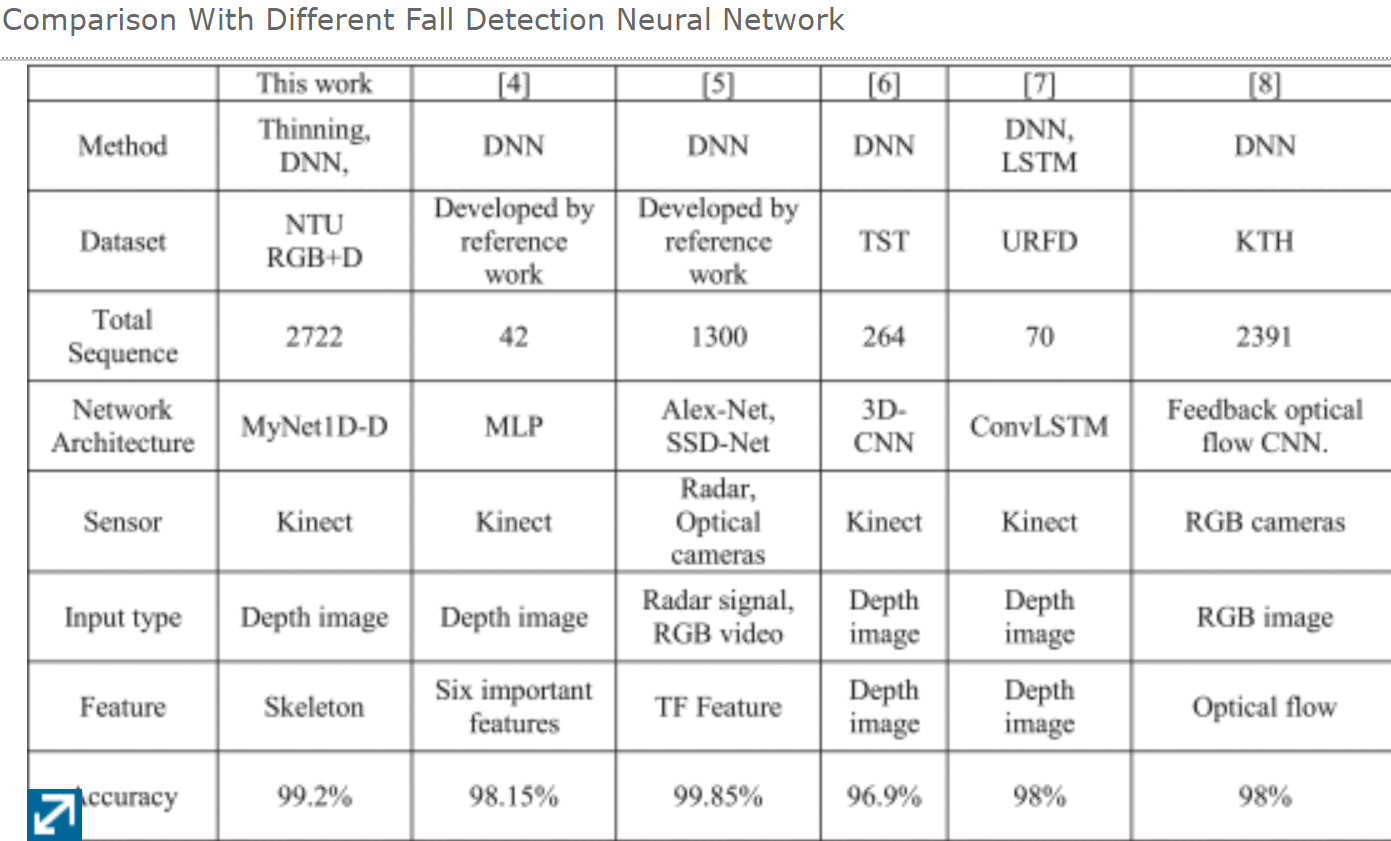
system: 15 frames per second in real-time
Conclusion
- depth image for skeleton extraction, conv1d for parameter pruning
- 15 frames per second for real-time implementation.
Paper VI: 3D skeletons
Human fall-down event detection based on 2D skeletons and deep learning approach
Previous
- Most of the existing skeleton-based action recognition approaches model actions based on well-designed hand-crafted local features.
- depth value+HMM etc.
- single RGB image + NNs (CNNs, RNNs)
Idea
- CNN for extracting skeletons and LSTM for final detection
- Skelton extractor:
- input: 2D RGB image (1920*1080)
- DeeperCut skeleton extraction: resnet backbone, output 14 joints (“forehead”, “chin”, and left and right “shoulder”, “elbow”, “wrist”, “hip”, “knee”, “ankle”, the mean of hip, the mean of chin and central-hip. The last two joints are for robustness with respect to background, so as to build a translation-invariant skeleton model).
- LSTM:
- input: 8 frames, try to classify 5 actions. Supervised training. (8*28), where (28=2*14)
Experiments
- 800 training, 255 validation and 250 test. Manually remove the wrong skeletons (incomplete skeletons) by like a threshold (sum of the distances between each joint and the centroid is calculated)
- trigger rule: during the last 30 outputs,
- current-time output is “lying” and the previous 19 outputs contain more than 14 “danger” statuses, an alarm will be triggered.
- current output belongs to “safe” status and the previous 8 outputs contain over 5 “safe” statuses, then the alarm signal will be reset.
- 8 frames per second
Human Activity Recognition
Paper VII
Paper VII: Vision-based human activity recognition: a survey
Goal
review and summarize the progress of HAR systems from the computer vision perspective.
HAR
- Related: determining and naming activities using sensory observations
- Goal: labeling the same activity with the same label even when performed by different persons under different conditions or styles
- Methods: usually by an activity detection task, which includes the temporal identification and localization. Formally, the activity recognition task is divided into classification and detection
- HAR systems are influenced by two technologies: contact-based and remote methods.
- contact-based: require the physical interaction of the user with the command acquisition machine or device. Sensors like accelerometers, multi-touch screens etc. But it is not that popular now, cause the complicated sensors and price to make it easily to be accepted and wore
- remote based: vision, societal trust, no requirement of ordinary users and thus non-intrusive
- Contributions:
- New update on this rarely focused theme
- thoroughly analysis
- multiple classification methods so as to analyze: detection, tracking and classification stages; feature extraction progress; input data modalities; supervision level; evaluation methods;
Benchmarks
- CONVERSE: complex conversational interactions
- ALSAN:
Previous
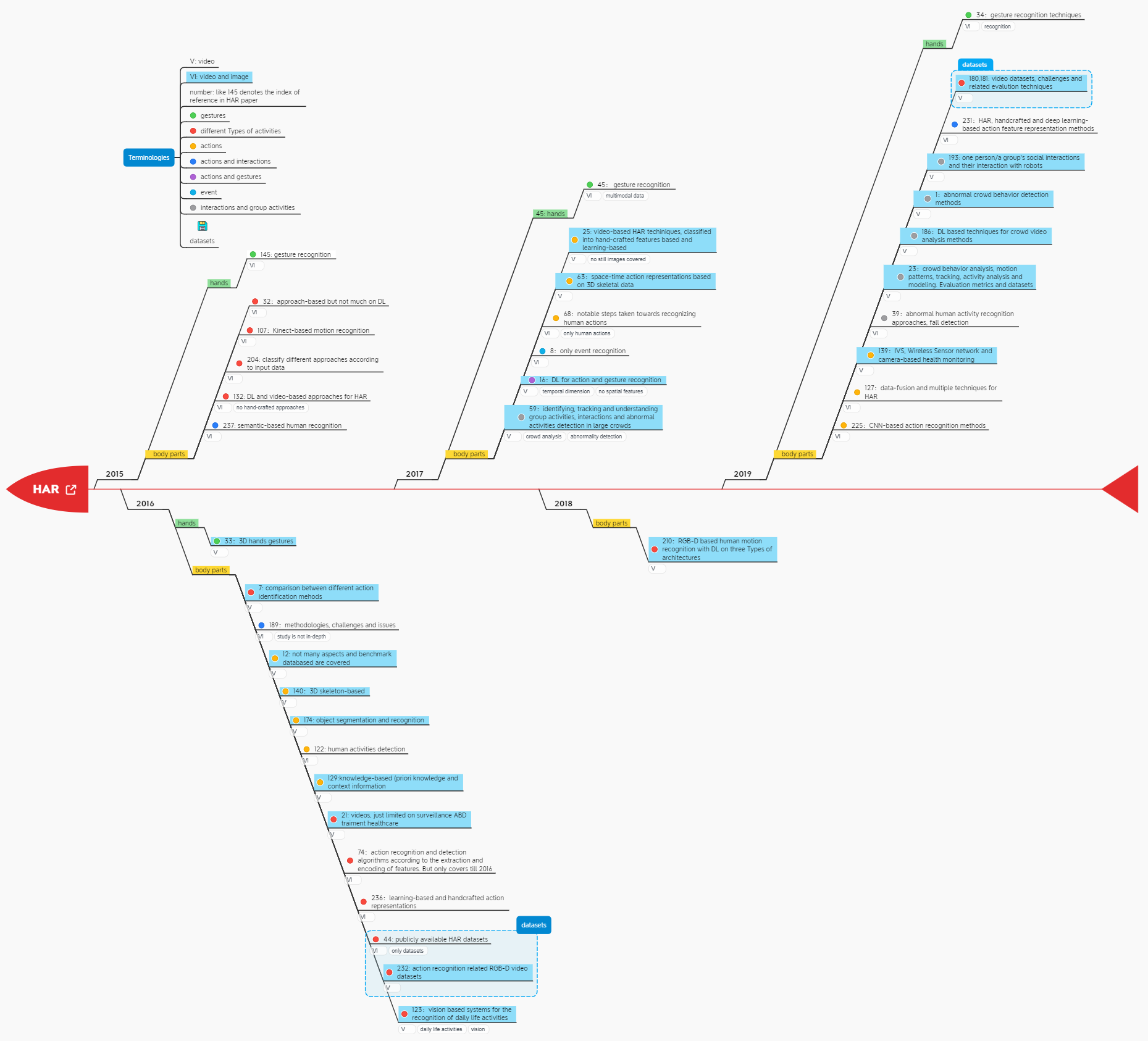
HAR approaches
HAR approaches according to feature extraction process
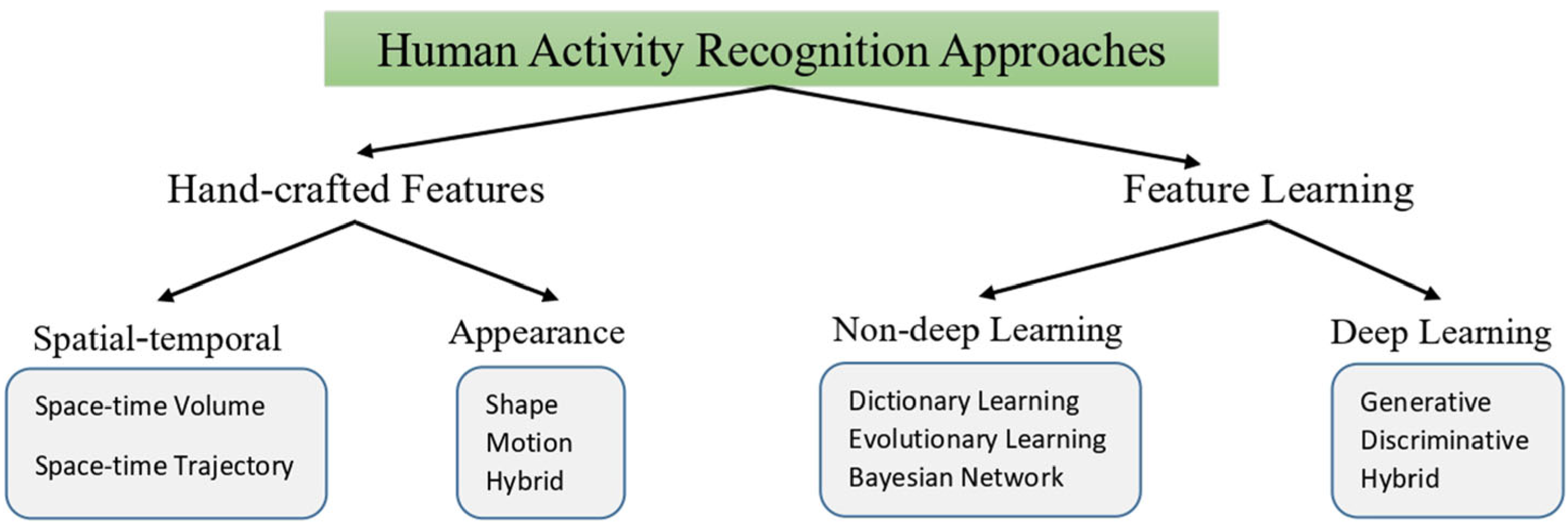
The main steps of handcrafted-based features:
- foreground detection that corresponds to action segmentation
- feature selection and extraction by an expert
- classification of action represented by the extracted features
The spatial and temporal representations of actions
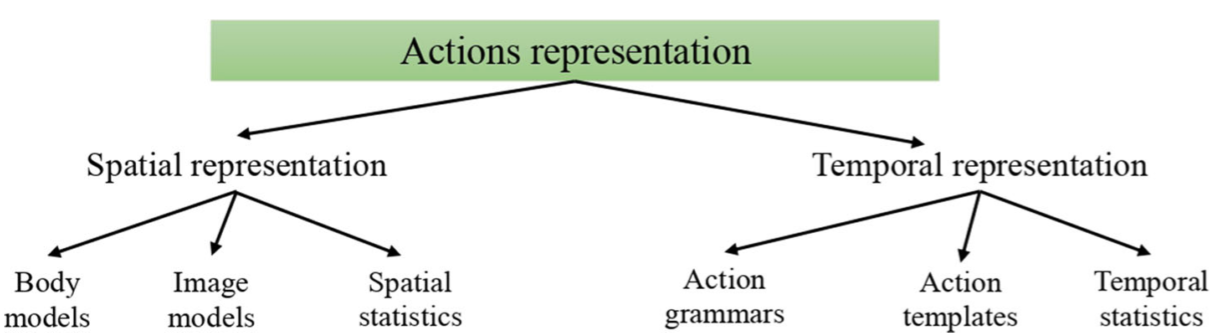
Based on spatial cues (spatial representation )
- body models: use kinematic joint model, can be 3D model or directly recognize on 2D model
- image models: holistic representation of actions that use a regular grid bounded by ROI centered around the person. E.g., silhouettes, contours, motion history images, motion energy images and optical flow.
- spatial statistics: use a set of statistics of local features from the surrounding regions. E.g., calculated spatial-temporal interest points (STIP) of the image and assign each region to a set of features.
- volume-based: rely on features like texture, color, posture etc. Recognizing actions by the similarity between two action volumes. Only works fine on simple action or gesture. Like SIFT.
- trajectory-based: represent joint positions with 2D or 3D points and then track them. The tracked changes in the posture is used for classification. Noise, view and /or illumination changes robust. Like HOG, HOF etc.
Based on temporal cues (temporal representation )
- action grammars: represent the action as a sequence of moments, and each moments is described by its own appearance and dynamics. Features are grouped into similar configurations called states and temporal transition between these states are learned. Like HMM, CRF, regression models and context-free grammars
- action templates: representing the appearance of temporal blocks of features and dynamics called templates. Take representations of dynamics from several frames. Methods like Fourier Transform, Wavelet representations and trajectories of body parts are templates that cane be used
- temporal statistics: use statistical models to describe the distributions of unstructured features over time.
Appearance based approaches: can be classified according to either shape or motion based characteristics.
Use 2D or 3D depth images and are based on shape features, motion features or any combination of both features. One advance is the skeleton-based recognition. Methods of it can be classified as (1) joint locations: consider the skeleton as a set of points; (2) joint angles: assume the human body as a system of rigid connected segments and the movement as an evolution of their spatial configuration.
- shape based methods: local shape features such as contour points, local region, silhouette and geometric features from the Human image or video after foreground segmentation.
- motion based methods: optical flow and motion history volume from extracting action representation. methods like vector quantization of motion descriptors is used for action recognition. It uses histograms of optical flow and classifiers of bag-of-words.
- hybrid methods: shape + motion features
Feature learning based methods for extracting representations
- traditional approaches
- dictionary learning: provides a sparse representation of the input data. It's proved that the use of over-complete dictionaries can produce even more compact representations
- genetic programming: search a space of possible solutions without having any prior knowledge and can discover functional relationships between features in data enabling its classification. GP is used to construct holistic descriptors that allow to maximize the performance of action recognition tasks.
- bayesian networks: PGMs, some use PGMs to represent and capture the semantic relationships among action units, and the correlations of the action unit intensities
- deep-learning-based methods
- generative methods: the main goal of these models is to understand the data distribution including the features that belong to each class. Methods like AE, VAE, GANs
- discriminative methods: DNN,RNN, CNN. E.g., propose long-term temporal convolutions + high-quality optical flow
- hybrid models
- traditional approaches
HAR approaches according to the recognition stages
- First stage methods (detection)
- skin color: used to detect the desire body part. May face problems since the chosen color space or when the objects of the scenario whose color is close to that of the skin. Seems not that robust
- ????Shape: the contours of the body part shape. This kind of methods are independent of the camera view, skin color and conditions of lighting.
- pixel values: appearance is represented as pixel values change between images of a sequence according to the activity
- 3d models: build matches between characteristics of the model based on various features of the images. These methods are independent ode the viewpoint
- motion: Using like the difference in brightness of pixels of two successive images
- ????anisotropic-diffusion: based on the extension of the successful anisotropic diffusion based segmentation to the whole video sequence to improve the detection
- Second stage methods (tracking)
temporal based methods: models are used to follow body parts
- features tracking based on the correlation: try to track the regions that contains body parts. These models require the part being tracked remains in the same neighborhood in the successive images. E.g., use 3D information of depth maps; optical flow
- contours based tracking: snakes . initially place a contour close to the ROI (region of interest ), then it's warped in an interactive way using active shape models in each frame to make to snake converge. Sensitive to color intensity variations and smoothing and softening of contours
optimal estimation
- evaluate the state of moving systems from series of measures. In HAR, they are used to estimate the movements of the human body. In real-time systems. Limitations against cluttered backgrounds.
- similar to KF
particle filters
following the body parts and their configurations in complex environments. The location of one body part is modelled by a set of particles
cam shift
based on mean shift algorithm (it uses the models of appearance based on density to represent the targets).
- Third stage methods (classification)
- SVM: used with kernel like Gaussian, RBF or linear kernel
- Naive Bayesian classifier:
- KNN: sensitive to local fatal structure
- Kmeans: sensitive to data structures.
- mean shift clustering: no requirement of prior knowledge about the number of clusters and no limit of the forms
- machines finite state: states (the static gestures and postures) and transitions (temporal and /or probabilistic constraints). However, the models need to be changed everytime a new gesture appears. Computational expensive.
- HMMs:
- dynamic time wrapping: calculates the distances between each pair of possible points from two signals. Used for estimating and detecting the movement in a video sequence
- NNs
HAR approaches according to the source of the input data
- Uni-modal methods
- space-time methods: time and the 3D representation f the body to locate activities in space. But sensitive to noise and occlusion. Cannot works on complex actions
- stochastic methods: models like Markov Model. The training is difficult cause the amount of parameters.
- rule-based methods: characterize the activity using a set of rules or attributes
- shape-based methods: shape features to represent and recognize activities. Dependent on the viewpoint, occlusion, people clothing and sensitive to lighting variations
- Multi-modal methods
- emotional methods: associate visual and textual features
- behavior methods: recognize the behavior methods.
- social networks-based methods: allow recognition of social events and interactions
HAR approaches according to the ML supervision level
- supervised: mostly used to classify and recognize short term actions
- unsupervised: outperform on finding spatio-temporal patterns of motion. computationally complex, less accurate and trustworthy.
- semi-supervised: hybrid.
Activities type
Divided by the complexity

- elementary human actions: simple atomic activities
- gestures: a language or part of the non-verbal communication which can be employed to express significant ideas or orders
- behaviors: a set of physical actions and reaction of individuals in specific situations
- interactions: reciprocal actions or exchanges between two entities or more
- group actions:
- events: social actions between individuals
Body parts
- hand gestures: be tracked to detect the communication between individuals
- foot: detect shifting and movements of people or Other actions
- facial expressions: interpret specific Types of human activities, especially for handicapped or disabled people
- full body: posturers and human actions by the whole body
The Types of Input Data
image or videos
- HAR on static images: when activity is distinguishable compared to others by its characteristic.
- HAR by videos: offer extra information related to prior and post event, then the relation between two successive frames can be established
single viewpoint or multi-view acquisition
- single view acquisition
- multiple view acquisition
Evaluations
Validation means
- One platform, validated on different Types of datasets (differ on actions) acquired by this platform.
- Different platforms, different datasets but all be evaluated so as to test the generalization across datasets
- Compared with results in literature
Datasets (Benchmarks)
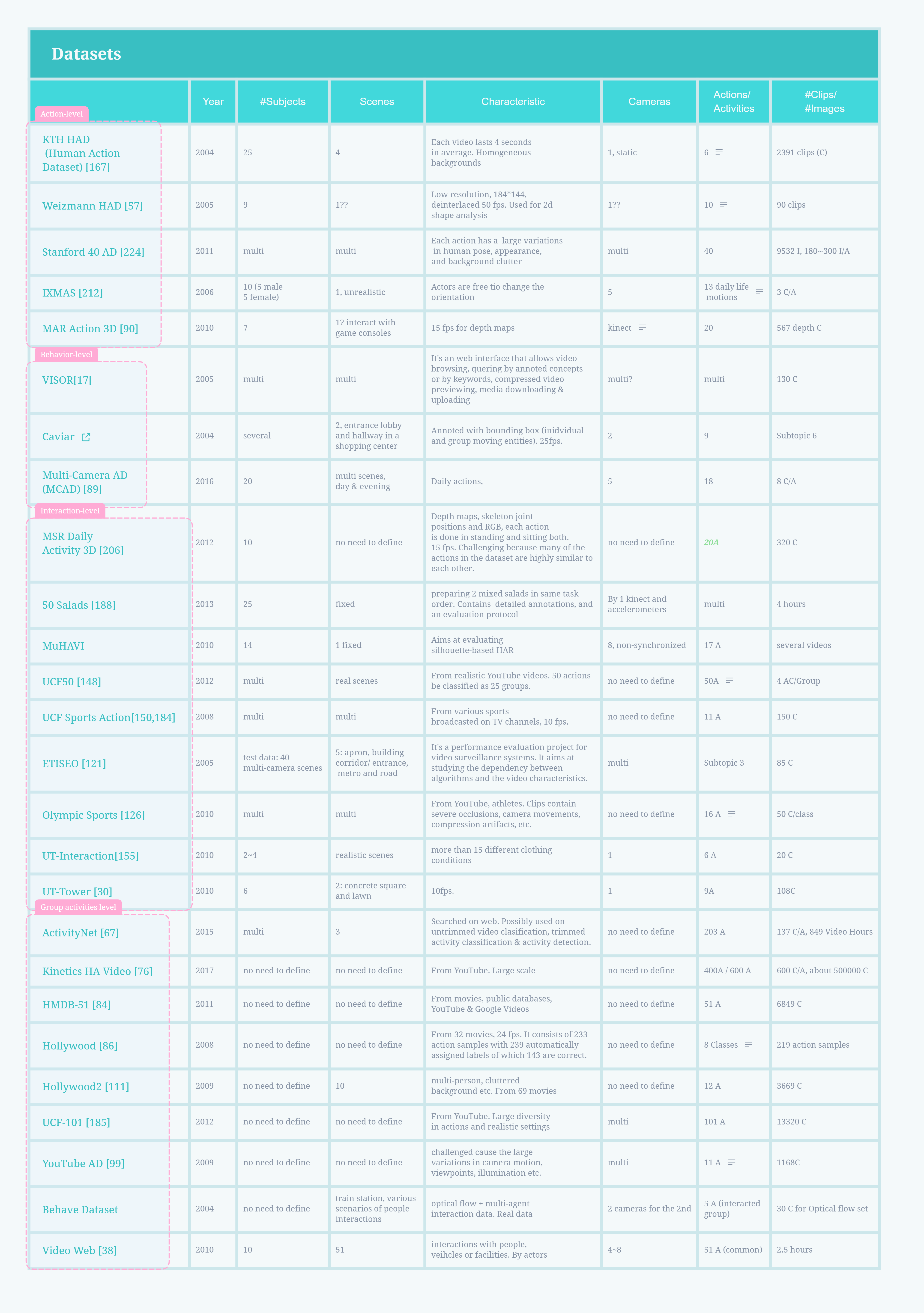
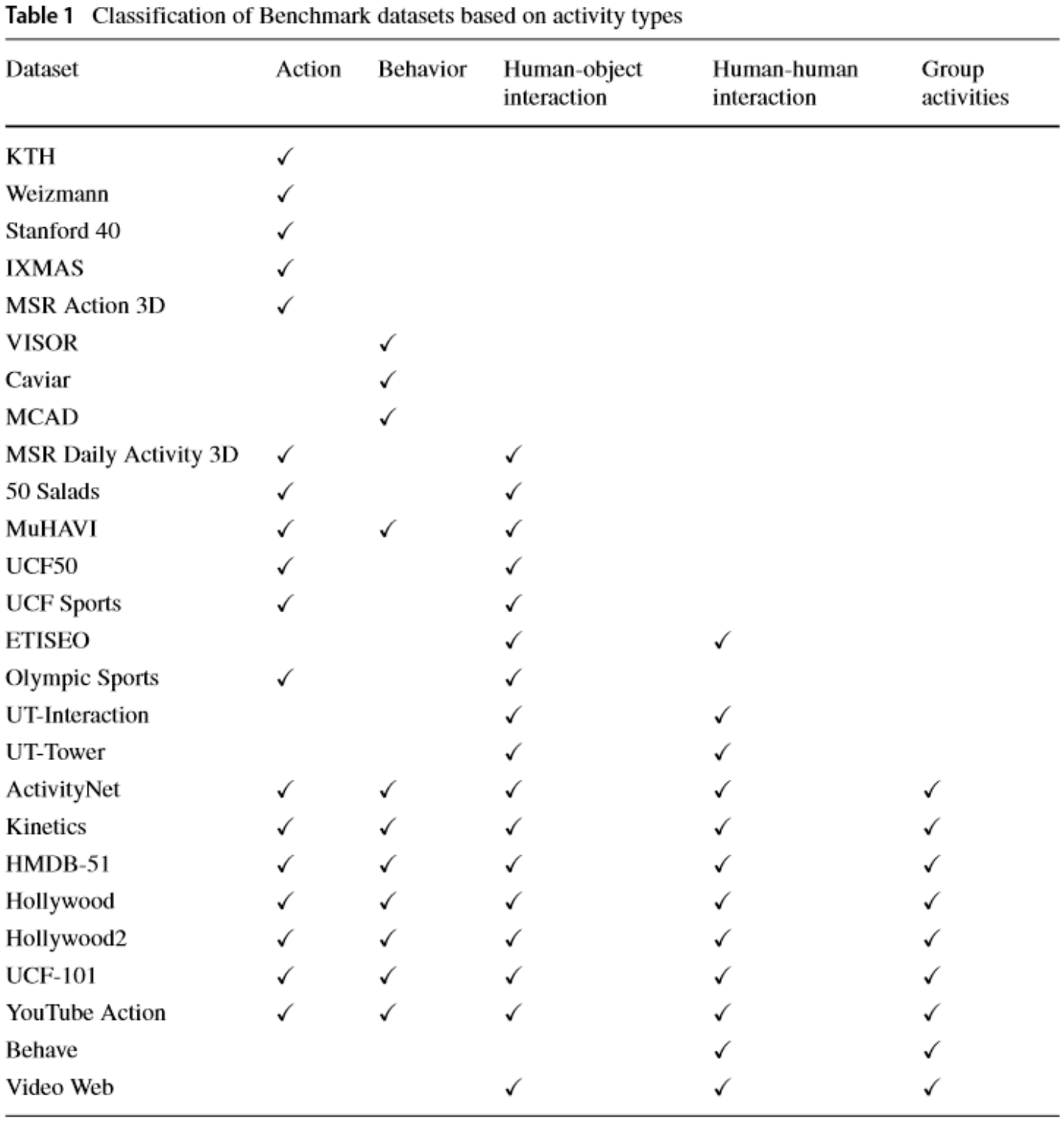
Evaluation metrics
sensitivity: also known as TP, recall or probability of detection. It determines the failure of the system to detect actions
\(Sensitivity =\frac{TP}{TP+FN}\)
precision: also known as PPV (positive prediction value). \((1-precision)\) determines the probability of the recognizer incorrectly identifying a detected activity
\(Precision=\frac{TP}{TP+FP}\)
Specificity: also known as false positive rate (FPR).
\(Specificity=\frac{TN}{TN+FP}\)
Negative predictive value (NPV): also known as negative precision. It measures the system sensitivity to negative class.
\(NPV=\frac{TN}{TN+FN}\)
F_measure: the harmonic mean of precision and recall. It gives information of tests accuracy. Best with 1 and worst with 0.
$F_measure=2 $
Accuracy: the percentage of correct predictions relative to the total number of samples
\(Accuracy =\frac{\#CorrectPredictions}{\#Predictions}\\Accuracy =\frac{TP+TN}{\#samples}\)
Likelihood ratio: the likelihood of an activity predicted when it matches the ground truth compared to the likelihood when it's predicted wrongly.
\(LR+=\frac{Sensitivity}{1-Specificity},\\ LR-=\frac{1-Sensitivity}{Specificity}\)
AUC: it's 1 if predicted perfectly.
Confusion matrix
IoU: intersection over Union, also known as Jaccard index or Jaccard similarity coefficient.
\(IoU=\frac{AreaOfOverlap}{AreaOfUnion}\)
Limitations and Challenges
Limitations
Show various issues that may affect the effectiveness of HAR system.
- specific to the methods used during the various phase of the recognition process.
- methods based on the form or the appearance
- like colorimetric segmentation: confuse the objects of the scene and body parts
- variation in appearance or clothing of people
- methods based on the form or the appearance
- related to the acquisition devices, experimentation environment or various applications of the system.
- light variations: affect the image quality and then features
- perspective change: if data is acquired by single view it would be a big problem
- self-occlusion: body parts occlude each other
- occlusion of another object
- partial occlusion of human body parts
- variety of gestures linked to the complex structure of human activities and the similarity between classes of different actions.
- due to data association
- noise, complex or moving backgrounds and unstructured scenes, and scale variation
- rely on their own recorded dataset to test performance
- call of a benchmark
Challenges
- the requirement of continuous monitoring and generate reliable answers at the right time
- modeling and analyzing interactions between people and objects with an appropriate level of accuracy
- societal challenges: acceptance by the society, privacy, side effects of installation
- privacy: HAR systems on smartphones may be a way out
- HAR system should be independent on users' age, color, size or capacity to use
- gestures independence and gestures spotting from continuous data streams
- detect and recognize various gestures under different background conditions
- tolerant with the scalability and growth of gestures
- context-aware: improve applications in its domain
- daily life activities: complex videos and hard to be modeled; overlapping of starting and ending time of each particular activity; discrimination between intentional and involuntary actions
- HAR through missed parts of video, recognition more than one activities performed by one person at the same time, early recognition and prediction of actions
- The implementation of DL HAR system: memory constraint, high number of parameters update, collection an fusion of large multi-modal variant data for the training process, deployment of different architectures of DL based methods in smartphones or wearable devices