Paper Graph Embedded Pose Clustering for Anomaly Detection
Code here
Why?
Previous work
Anomaly detection task
- Fine-grained anomaly detection: Detecting abnormal variations of an action: e.g. an abnormal type of walking
- Coarse-grained anomaly detection: Defining normal actions and regard other action as abnormal. Aka there are multiple poses regarded as normal actions, rather than a single normal action.
Video anomaly detection
- Reconstructive models: learn a feature representation for each sample and attempt to reconstruct a sample based on that embedding, often using Autoencoder. Samples poorly reconstructed are considered anomalous.
- Predictive models: model the current frame based on a set of previous frames, often relying on recurrent neural networks or 3D convolutions. Samples poorly predicted are considered anomalous.
- Reconstructive + predictive models
- Generative models: used to reconstruct, predict or model the distribution of the data, often using Variational Autoencoders (VAEs) or GANs. E.g. the differences in gradient-based features and optical flow.
GNNs
The point is the weighted adjacency matrix.
- Temporal and multiple adjacency extensions. (ST-GCN)
- Graph attention networks. (2s-AGCN)
Deep clustering models
Provide useful cluster assignments by optimizing a deep model under a cluster inducing objective.
Summary
- Observations
- Skeleton-based methods make the analysis independent of nuisance parameters such as viewpoint or illumination.
- Limitations
- Traditional RGB-based anomaly detection methods have to consider many trivial information (viewing direction, illumination, background clutter etc.), and those data are sparse in human pose.
Goals
Generating action words from skeleton-based graphs and then classify actions into normal and abnormal (anomaly detection). With an aim at it can work both on fine-grained and coarse-grained task.
How?
Idea
Map graphs into representation space and then cluster them so as to get action words. At last, Dirichlet process based mixture is used for classifying normal and abnormal.
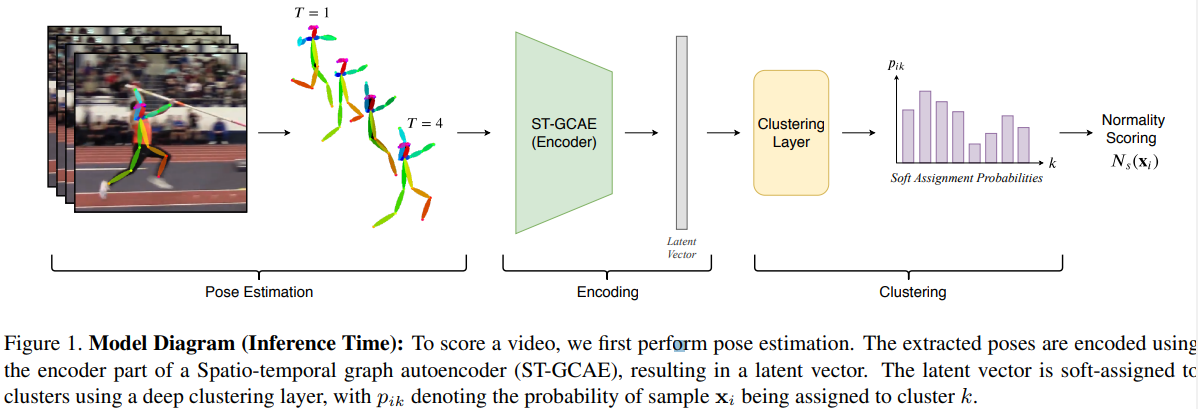
Data Preparation
- Similar skeleton graph as what used in ST-GCN.
Implementation
Backbone: ST-GCN
ST-GCAE network
GCN block
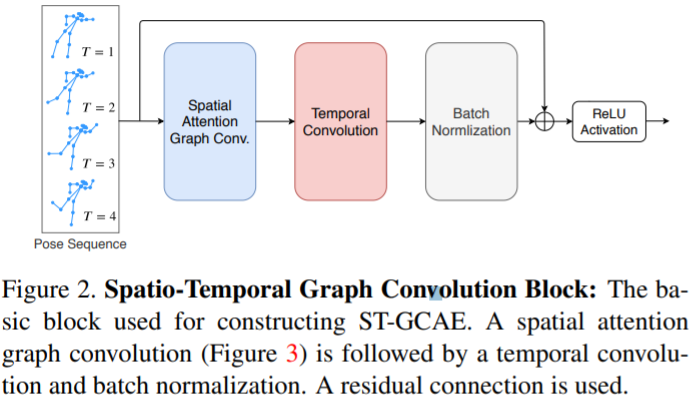
The block will be used in SAGC
SAGC block
Each adjacency type is applied with its own GCN, using separate weights.
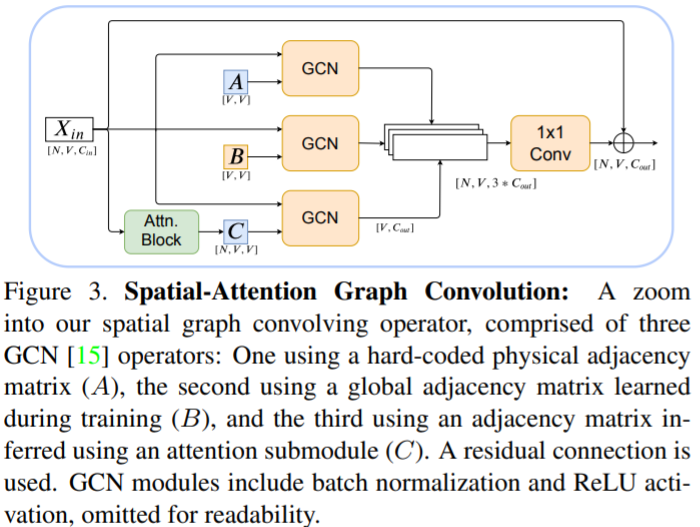
Adjacency matrices
matrix sharing level Dimension \(\mathrm{A}\) fixed and shared by all layers body-part connectivity over node relations \([V,V]\), \(V\) is the number of nodes \(\mathrm{B}\) individual at each layer, applied equally to all samples dataset level keypoint relations \([V,V]\) \(\mathrm{C}\) is different for different sample sample specific relations \([N,V,V]\), \(N\) is the batch size
ST-GCAE
The encoder uses large temporal strides with an increasing channel number to compress an input sequence to a latent vector. The decoder uses temporal up-sampling layers and additional graph convolutional blocks.
Deep embedded cluster
The input is the embedding from ST-GCAE, denoted as \(\mathrm{z}_i\) for sample \(i\)
Soft-assignment --clustering layer
The probability \(p_{ik}\) for the \(i\)-th sample to be assigned to the \(k\)-th cluster is:
\(p_{ik}=Pr(y_i=k|\mathrm{z}_i,\Theta)=\frac{exp(\theta^T_k\mathrm{z}_i)}{\sum\limits_{k'=1}^{K}exp(\theta^T_{k'}\mathrm{z}_i)}\), where \(\Theta\) is the clustering layer’s parameters. (Simple softmax)
Optimize clustering layer
- Objective: Minimize the KL-divergence between the current model probability clustering prediction \(P\) and a target distribution \(Q\). The target distribution aims to strengthen current cluster assignments by normalizing and pushing each value closer to a value of either 0 or 1.
- EM style. In expectation step, the entire model is fixed and the target distribution \(Q\) is updated. In maximization stage, the model is optimized to minimize the clustering loss \(L_{cluster}\).
Anomaly classifier--normality scoring??
- Two types of multimodal distributions. One is at the cluster assignment level; the other is at the soft-assignment vector level.
- DPMM based. Classifier is fitted by soft-assignment vector (e.g., for class \(i\) the softmax result) and then it can do inference.
Model
Feeding the embedding from ST-GCAE to clustering layer, then fixing decoder, fine-tune the encoder in ST-GCAE and clustering layer by combined loss. After fine tuning, using DPMM-based classifier for final inference.
Loss function
Reconstruction loss \(L_{rec}\): \(\ell_2\) loss between the original temporal pose graphs and those reconstructed by ST-GCAE, used in pre-training stage, for training the whole ST-GCAE.
Clustering loss \(L_{cluster}\), combined with reconstruction loss and used for fine-tuning encoder of ST-GCAE+clustering layer
\(L_{cluster}=KL(Q||P)=\sum\limits_i\sum\limits_kq_{ik}\log\frac{q_{ik}}{p_{ik}},\\ q_{ik}=\frac{p_{ik}/(\sum_{i'}p_{i'k})^{\frac{1}{2}}}{\sum_{k'}p_{ik'}/(\sum_{i'}p_{i'k'})^{\frac{1}{2}}}\)
Combined loss
\(L_{combined}=L_{rec}+\lambda\cdot L_{cluster}\), this loss is for training encoder and clustering layer, which means the decoder is fixed while using it.
Optimization
- encoder: reconstruction loss + cluster loss
- decoder: reconstruction loss
- clustering layer: cluster loss
Experiments
Dataset
- ShanghaiTech: 130 abnormal events captured in 13 different scenes with complex lighting conditions and camera angles.
- training set contains only normal examples
- test set contains both normal and abnormal examples
- 2D pose
- Kinetics-based: Kinetics-250 and NTU-RGBD. Actions in each set are sampled randomly or meaningfully. In Kinetics dataset, remove actions that focus only on slightly part joints' movements, like hair braiding.
- Few vs. Many: few normal actions (\(3\sim5\)) in the training set and many abnormal (\(10\sim 11\) hundreds) actions in the test set
- Many vs. Few: switch the training set and test set in experiment above.
- ShanghaiTech: 130 abnormal events captured in 13 different scenes with complex lighting conditions and camera angles.
Preprocessing
- Pre-extracting 2D pose from ShanghaiTech Campus
Input features
- The coordinates of joints
- For ShanghaiTech: The embeddings of the patch around each joint (from one of the pose estimation model's hidden layers)
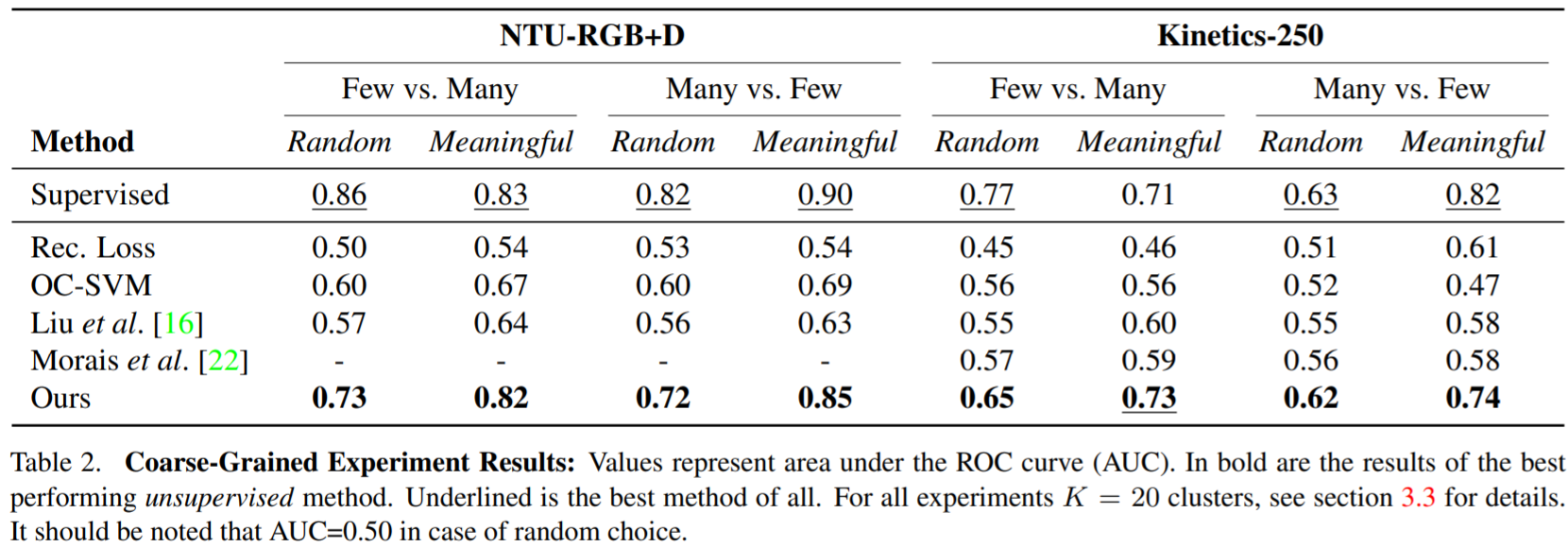
Test Algorithms on coarse-grained (Kinetics and NTU-RGBD)
Autoencoder reconstruction loss: ST-GCAE reached convergence prior to the deep clustering fine-tuning stage.
Autoencoder based one-class SVM: fit a one-class SVM using the encoded pose sequence representation
Video anomaly detection methods: Train Future frame prediction model and the skeleton trajectory model. Anomaly scores for each video are obtained by averaging the per-frame scores.
Classifier softmax scores: supervised baseline. Anomaly score is by either using the softmax vector's max value or by using the Dirichlet normality score
Test video in fixed size but with sliding-window if the test video with unknown frames
Evaluation metrics
- Frame-level score: the maximal score over all the people in the frame
- AUC as the combined score over all frames of one test
Summary
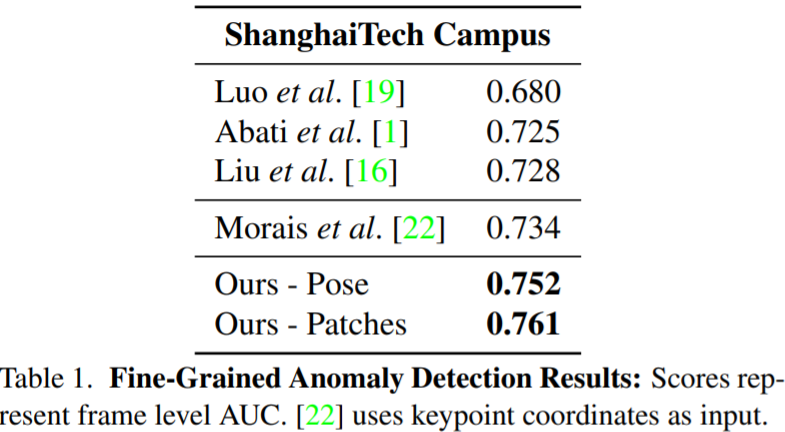
On ShanghaiTech (fine-grained): Patches ST-GCAE outstands.
On coarse grained dataset, ST-GCAE outperforms, but better on meaningful actions. A good skeleton help ST-GCAE (NTU-RGBD has better detection on skeletons cause the depth data is known.)
Failed cases: occlusions, high-speed action like cycling, non-person related abnormal like bursting into a vehicle.
Ablation study: adding some abnormal actions into normal actions
- ST-GACE on NTU-RGBD (only dropping, touching and Rand8 dataset are tested): ST-GCAE loses on average less than \(10\%\) of performance when trained with \(5\%\) abnormal actions added as noises.
Conclusion
- The use of embedded pose graphs and a Dirichlet process mixture for video anomaly detection;
- A new coarse-grained setting for exploring broader aspects of video anomaly detection;
- State-of-the-art AUC of 0.761 for the ShanghaiTech Campus anomaly detection benchmark.
Remarks
- The reconstruction (learning representations of graph) is mixed with clustering in the final loss, will this be good? Won't the trivial information of clustering influence the reconstruction?
- The training set for clustering layer is initialized by the K-Means centroids, won't the initialization methods matter?
- The embeddings of patches around each joint outperforms the simple joint coordinates