Paper Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition
Code here
Why?
Previous work
- Convolutional DL based methods manually structure the skeleton as a sequence of joint-coordinate vectors or as a pseudo-image, which is fed into RNNs or CNNs to generate the prediction.
- Skeleton-based action recognition
- Design handcrafted features to model human body, but they are barely satisfactory.
- DL-based: CNN-based methods are generally more popular than RNN-based methods. But both fail to fully represent the structure of the skeleton data.
- GCN-based: ST-GCN, eliminates the meed for designing handcrafted part assignment or traversal rules.
- GNNs
- Spatial perspective: directly perform the convolution filters on the graph vertexes and their neighbors, which are extracted and normalized based on manually designed rules.
- Spectral perspective: use the eigenvalues and eigenvectors of the graph Laplace matrices. They perform the graph convolution in the frequency domain with the help of graph Fourier transform.
Summary
- Observations
- The second-order information (the lengths and directions of bones) of the skeleton data, which is naturally more informative and discriminative for action recognition, is rarely investigated in existing methods.
- Limitations:
- Representing the skeleton data as a vector sequence or a 2D grid cannot fully express the dependency between correlated joints
- In GCN-based skeleton action recognition, the topology of the graph is set manually and thus may not be optimal for the hierarchical GCN and diverse samples in action recognition tasks.
- ST-GCN: 1) The skeleton graph is heuristically predefined and represents only the physical structure of the human body. 2) The fixed topology of graph limiting the flexibility and capacity to model the multilevel semantic information. 3) One fixed graph structure may not be optimal for all the samples of different action classes. Like hands-related actions and legs-related actions
Goals
Propose a improved ST-GCN (graph convolutional based model), so as to use 2nd order information and improve the accuracy of action recognition based on skeletons.
Make the graph is unique for different layers and samples.
How?
Idea
Modification on ST-GCN
- Two types of graphs:
- Global graph: represents the common pattern for all the data
- Individual graph: represents the unique pattern for each data
- Second-order information: the length and directions of bones are formulated as a vector pointing from its source joint to its target joint.
Data Preparation
- The structure of the graph follows the work of ST-GCN.
A look at ST-GCN
Graph convolution in ST-GCN: \(f_{out}(v_{ti})=\sum\limits_{v_{tj}\in \mathcal{B}_i}\frac{1}{Z_{ti}(v_{tj})}f_{in}(v_{j})\cdot \mathrm{w}(l_{ti}(v_{tj}))\), follows spatial configuration partitioning.
- Graph convolution in spatial dimension
\(f_{out}=\sum\limits_{k}^{K_v}\mathrm{W}_k(f_{in}\mathrm{A}_k)\odot\mathrm{M}_k\), where \(\mathrm{M}_k\) is an \(N\times N\) attention map that indicates the importance of each vertex. \(\mathrm{A}_k\) determines whether there are connections between two vertexes and \(\mathrm{M}_k\) determines the strength of the connections.
- Graph convolution in temporal dimension: \(K_t\times 1\)convolution on the output feature map
The model is calculated based on a predefined graph, which may not be a good choice.
Implementation
Adaptive graph convolutional network (AGCN)
BN+9 of adaptive graph convolutional blocks + global average pooling + softmax classifier
Adaptive graph convolutional layer:

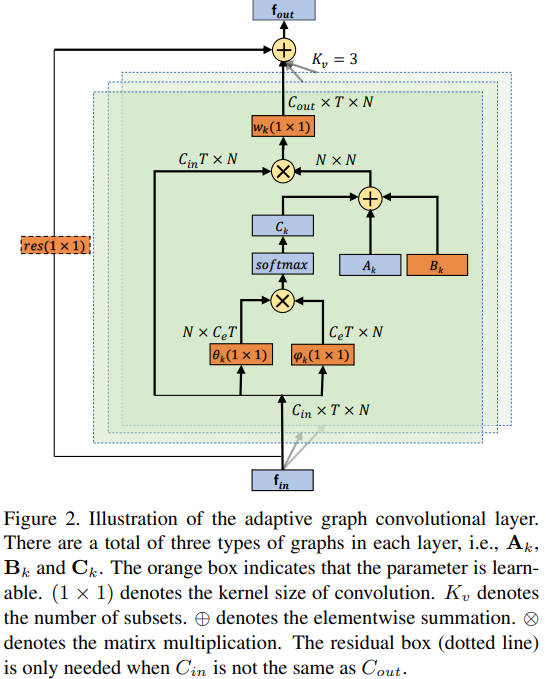
\(f_{out}=\sum\limits_{k}^{K_v}\mathrm{W}_kf_{in}(\mathrm{A}_k+\mathrm{B}_k+\mathrm{C}_k)\). The adjacency matrix is now divided into three parts
\(\mathrm{A}_k\): same as \(N\times N\) adjacency matrix \(\mathrm{A}_k\) in ST-GCN, it represents the physical structure of the human body.
\(\mathrm{B}_k\): An \(N\times N\) adjacency matrix. It's trainable. It acts as \(\mathrm{M}_k\) (attention mechanism) in ST-GCN, influenced by the connections between two joints and also the strength of the connections.
\(\mathrm{C}_k\): a similarity matrix calculated by the normalized embedded Gaussian function with vectors embedded by \(1\times 1\) convolutional layer.
\(\mathrm{C}_k=softmax(\mathrm{f}_{in}^T\mathrm{W}_{\theta k}^{T}\mathrm{W}_{\phi k}\mathrm{f}_{in})\), where \(\mathrm{W}_\theta,\mathrm{W}_\phi\) are the parameters of the embedding functions \(\theta,\phi\), respectively.
Adaptive graph convolutional block
Model: two stream networks
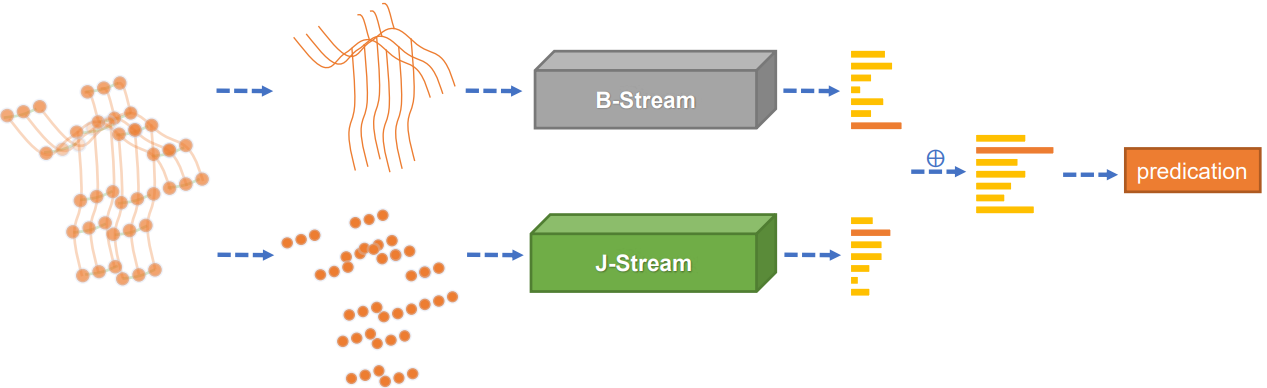
- J-stream: the input data are joints, as what's depicted in AGCN.
- B-stream: the input data are bones.
- A bone is the vector pointing from its source joint to its target joint. This vector will contain both length and direction of a bone. An empty bone is added so as to make sure the B-stream has similar quantity of input as J-stream.
Finally, the softmax scores of the two streams are added to obtain the fused score and do prediction.
Loss function
Cross-entropy
Why does it work?
- Considering bones (2nd information)
- Offers trainable attention matrix \(\mathrm{B}_k\) and the similarity evaluation of \(\mathrm{C}_k\) to estimate the strength of connection. Both of them offer more possible connections and provide more flexibility.
Experiments
- Dataset: Kinetics and NTU-RGBD
- NTU-RGBD: If the number of bodies in the sample is less than 2, the second body is padded with 0.
- Kinetics: Same data augmentation as done in ST-GCN.
- Training: SGD with Nesterov momentum (0.9), batch size is 64. The weight decay is set to 0.0001.
- NTU-RGBD: learning rate is set as 0.1 and is divided by 10 at the 30th epoch and 40th epoch. The training process is ended at the 50th epoch.
- Kinetics: The learning rate is set as 0.1 and is divided by 10 at the 45th epoch and 55th epoch. Training ends at the 65th epoch.
- Evaluation metrics
- NTU-RGBD: top-1 accuracy
- Kinetics : top-1 and top-5 accuracy
Ablation study
Adaptive graph convolutional block
Manually delete one of the graphs and estimate.
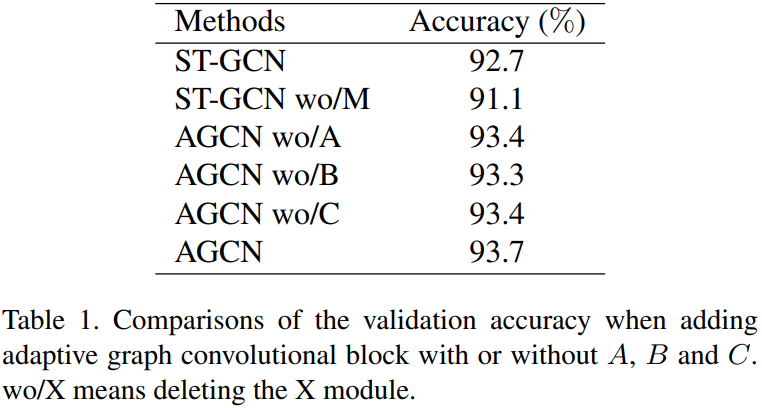
- Given each connection, a weight parameter is important, which also proves the importance of the adaptive graph structure
Visualization of the learned graphs
Denote the strength of joints by dot size, the bigger the stronger connection.
A higher layer in AGCN contains higher-level information, comparing the dot size in different layers
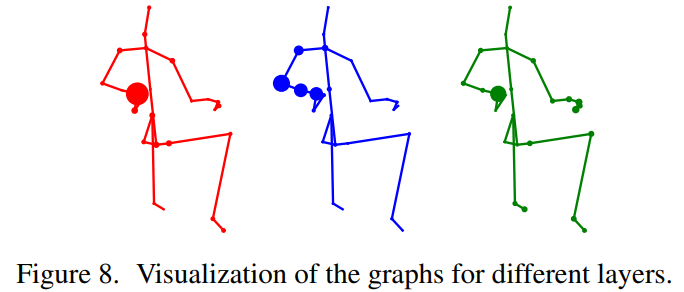
The diversity for different sample in the same layer is proved.
Two-stream framework
The two-stream method outperforms the one-stream-based methods either the J-stream or the B-stream.
Compared with SOTA
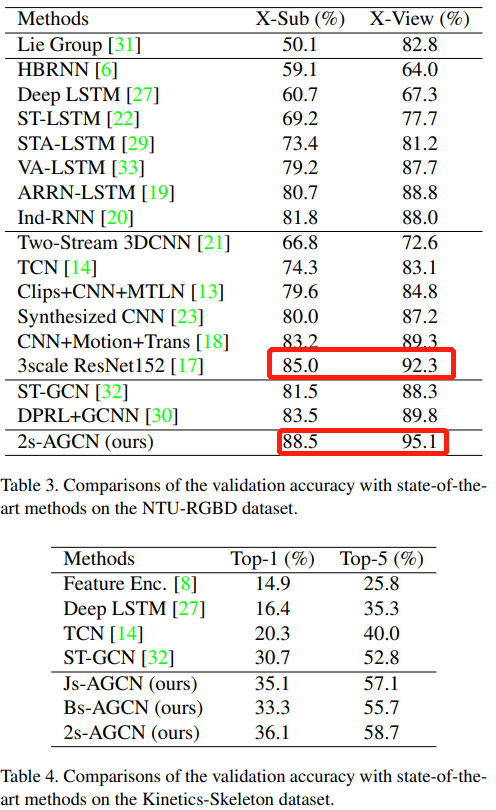
- Question 1: ResNet helps?
- Question 2: How about compared with methods based on RGB or optical flow ? In paper ST-GCN their model fails to those models.
Conclusion
- An adaptive graph convolutional network is proposed.
- The second-order information of the skeleton data is explicitly formulated and combined with the first-order information using a two-stream framework, which brings notable improvement for the recognition performance.
- On two large-scale datasets for skeleton-based action recognition, the proposed 2s-AGCN exceeds the SOTA by a significant margin.