Paper Revisiting Self-Supervised Visual Representation Learning
Code here
Why?
Previous work
- robotics: the result of interacting with the world, and the fact that multiple perception modalities simultaneously get sensory inputs are strong signals for pretext
- videos: the synchronized cross-modality stream of audio, video, and potentially subtitles, or of the consistency in the temporal dimension
- image datasets:
- Patch-based methods: E.g.: predicting the relative location of image patches; "jigsaw puzzle"
- Image-level classification tasks:
- RotNet, create class labels by clustering images, image inpaiting, image colorization, split-brain and motion segmentation prediction;
- Enforce structural constraints on the representation space: an equivariance relation to match the sum of multiple tiled representations to a single scaled representation; predict future patches in via autoregressive predictive coding
- Combining multiple pretext task: E.g. extend the “jigsaw puzzle” task by combining it with colorization and inpainting; Combining the jigsaw puzzle task with clustering-based pseudo labels ( Jigsaw++) ; make one single neural network learn all of four different SSL methdos in a multi-task setting; combined the selfsupervised loss GANs objective
Summary
- Observations
- Expensive labeled data for supervised task
- Limitations:
- Previous works mostly concentrate on pretext task, but didn't pay much attention to the choice of backbones etc.
Goals
An optimal CNN architecture for pretext task, investigating the influence of architecture design on the representation quality.
How?
Idea
- a comparison of different self-supervision methods using a unified neural network architecture, but with the goal of combining all these tasks into a single self-supervision task
Implementation
Family of CNNs
variants of ResNet:
ResNet50, the output before task-specific logits layer is named as \(pre-logits\). explore \(k \in \{4, 8, 12, 16\}\), resulting in pre-logits of size \(2048, 4096, 6144\) and \(8192\) respectively. \(k\) is the widening factor.
ResNet v1: ???batch normalization (BN) right after each convolution and before activation???
ResNet v2: ?
ResNet (-): without ReLU preceding the global average pooling
a batch-normalized VGG architecture since VGG is structurally close to AlexNet. BN between CNN and activation, VGG19.
RevNets: stronger invertibility guarantees so as to compare with ResNets. The residual unit used here is equivalent to double application of the residual unit.
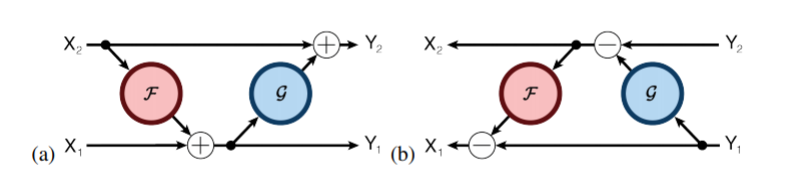 , check here for details. Apart from this slightly complex residual unit, others are the same as ResNet.
, check here for details. Apart from this slightly complex residual unit, others are the same as ResNet.
Family of pretext tasks
- Rotation: same as RotNet, \(\{0^{\circ}, 90^{\circ}, 180^{\circ}, 270^{\circ}\}\)
- Exemplar: triplet loss
- Jigsaw: recover relative spatial position of 9 randomly sampled image patches after a random permutation of these patches was performed. Patches are sampled with a random gap between them. Each patch is then independently converted to grayscale with probability \(\frac{2}{3}\) and normalized to zero mean and unit standard deviation. Extract final image representations by averaging representations of 9 cropped patches.
- Relative patch location: predicting the relative location of two given patches of an image. Extract final image representations by averaging representations of 9 cropped patches.
Evaluation of the quality of learned representations
- Idea: Using learned representations for training a linear logistic regression model to solve multiclass image classification tasks (downstream tasks). All representations come from pre-logits level.
- Details: the linear logistic regression model is trained by L-BFGS. But for comparison, using SGD with momentum and use data augmentation during training.
Experiments
- Datasets
| Datasets | Train | Test |
|---|---|---|
| ImageNet | training set | Most on validation set, only Table 2 on official test set |
| Places 205 | training set | Most on validation set, only Table 2 on official test set |
Pretext? CNNs? Downstream?
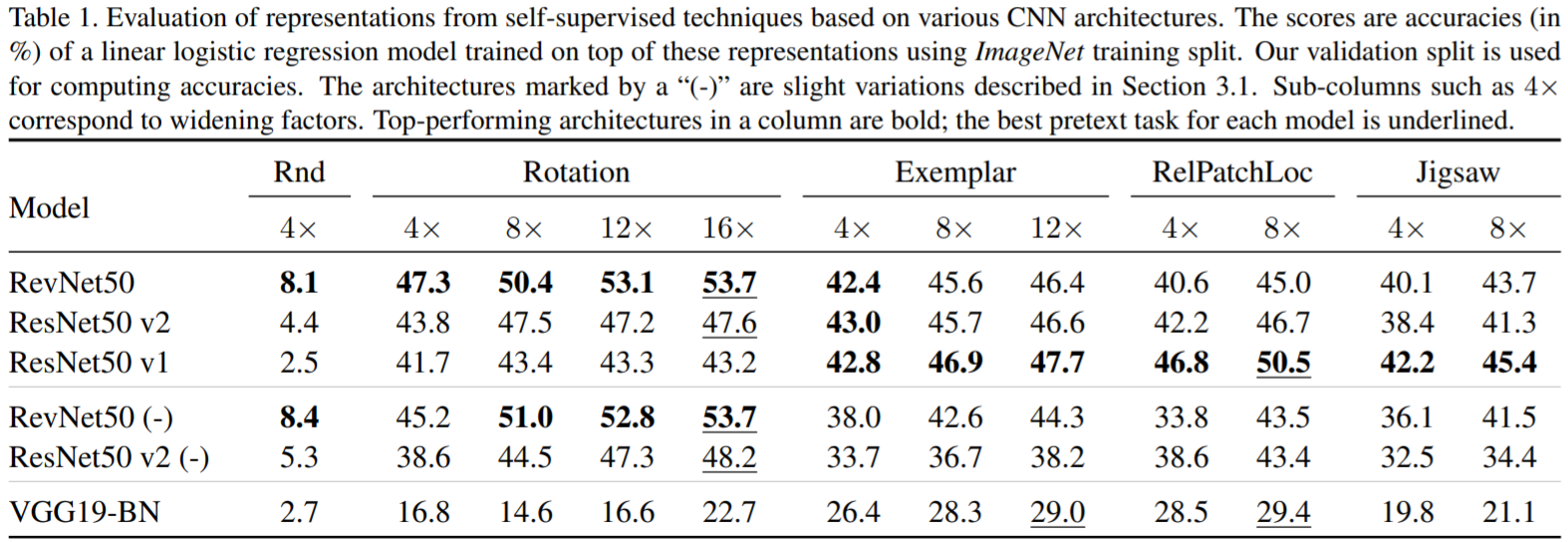
Pretext and its preferred CNN architecture: neither is the ranking of architectures consistent across different methods, nor is the ranking of methods consistent across architectures.
The generalization of representations from pretext tasks: each pretext task can be generalized to other dataset. Check the trendings in figure 2.
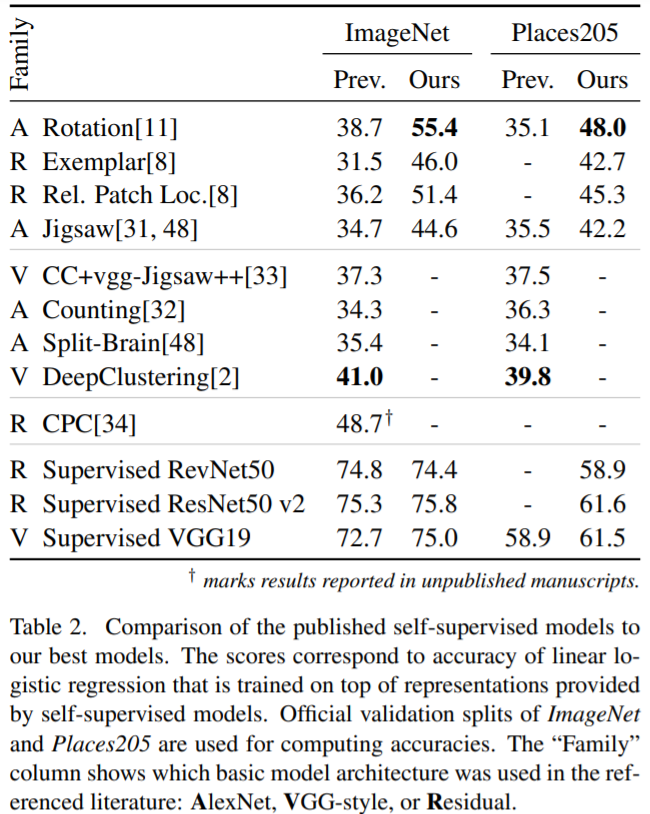
Optimal CNNs for Pretext and downstream tasks: not consistent. But after selecting the right architecture for each self-supervision and increasing the widening factor, models significantly outperform previously reported results.
Better performance on the pretext task does not always translate to better representations: Performance on pretext cannot be used to reliably select the model architecture.
CNNs architecture
- Skip-connection: For VGG, representations deteriorate towards the end of the network cause models specialize to the pretext task in the later layers. ResNet prevent this deterioration. They argue that this is because ResNet’s residual units being invertible under some conditions and confirm this by RevNet.
- Depth of CNNs: For residual architectures, the pre-logits are always best.
- Model-width and representation size:
- whether the increase in performance is due to increased network capacity or to the use of higher-dimensional representations, or to the interplay of both? To answer it, authors disentangle the network width from the representation size by adding an additional linear layer to control the size of the pre-logits layer.
- Model-width and representation size both matter independently, and larger is always better.
- SSL techniques are likely to benefit from using CNNs with increased number of channels across wide range of scenarios, even under low-data regime.
Evaluate the quality of representations
- A linear model is adequate: MLP provides only marginal improvement over the linear evaluation and the relative performance of various settings is mostly unchanged
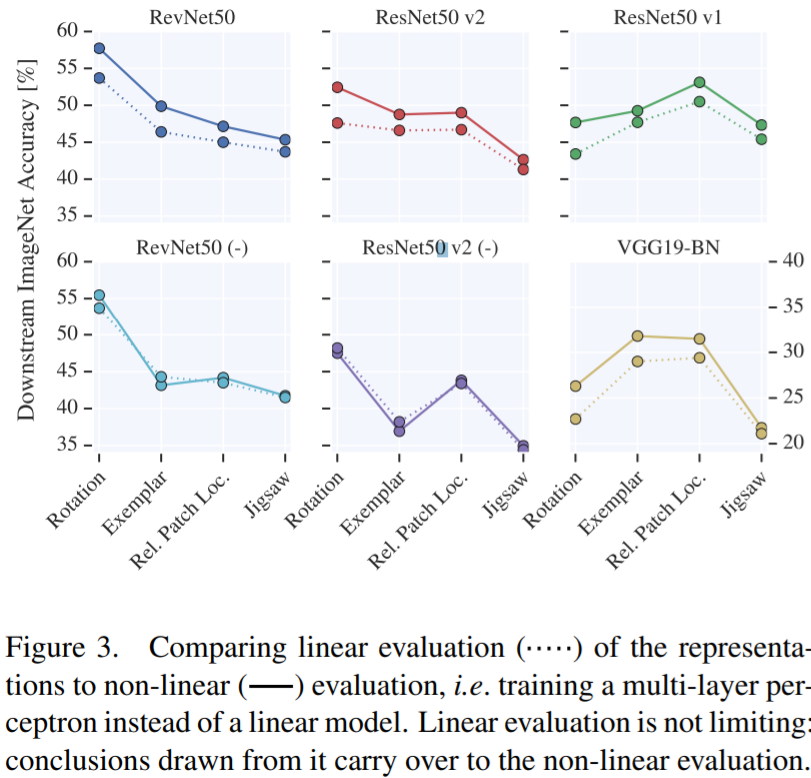
- To train linear model, SGD optimization hyperparameters: very long training (≈ 500 epochs) results in higher accuracy
Conclusion
- Most affect performance in the fully labeled setting, may significantly affect performance in the selfsupervised setting.
- the quality of learned representations in CNN architectures with skip-connections does not degrade towards the end of the model.
- Increasing the number of filters in a CNN model and, consequently, the size of the representation significantly and consistently increases the quality of the learned visual representations
- The evaluation procedure, where a linear model is trained on a fixed visual representation using stochastic gradient descent, is sensitive to the learning rate schedule and may take many epochs to converge
- neither is the ranking of architectures consistent across different methods, nor is the ranking of methods consistent across architectures.-->pretext tasks for self-supervised learning should not be considered in isolation, but in conjunction with underlying architectures.