Paper Unsupervised Representation Learning by Predicting Image Rotations
Codes here
Why?
Previous work
How to get a high-level image semantic representation using unlabeled data
- SSL: defines an annotation free pretext task, has been proved as good alternatives for transferring on other vision tasks. E.g.: colorize gray scale images, predict the relative position of image patches, predict the egomotion (i.e., self-motion) of a moving vehicle between two consecutive frames.
Summary
- Observations
- the attention maps are equivariant w.r.t. the image rotations, check appendix A.
- Limitations
- supervised feature learning has the main limitation of requiring intensive manual labeling effort
Goals
Provide a "self-supervised" formulation for image data, a self defined supervised task involving predicting the transformations used for image. The model won't have access to the initial image.
How?
Idea
- Concretely, define the geometric transformations as the image rotations by 0, 90, 180, and 270 degrees. Thus, the ConvNet model is trained on the 4-way image classification task of recognizing one of the four image rotations.
Implementation
Data preparation
2D image Rotation
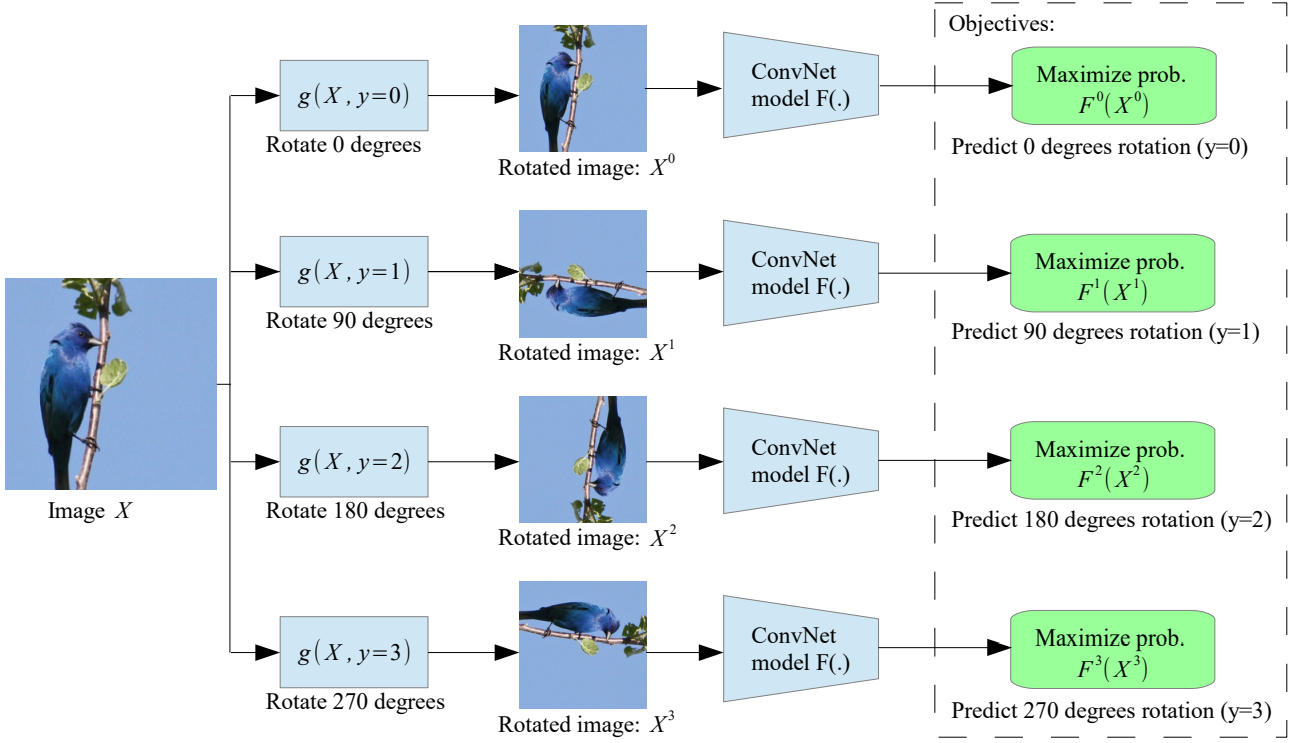
Operations Implementation +90 transpose then flip vertically +180 flip vertically then flip horizontally +270 flip vertically then transpose
Learning algorithm
Loss function:
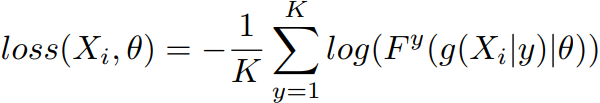 , where \(F(\cdot)\) is the predicted probability of the geometric transformation with label \(y\) and \(\theta\) are the learnable parameters of model \(F(\cdot)\), and \(g(X_i|y)\) is the transformed image with transformation \(y\).
, where \(F(\cdot)\) is the predicted probability of the geometric transformation with label \(y\) and \(\theta\) are the learnable parameters of model \(F(\cdot)\), and \(g(X_i|y)\) is the transformed image with transformation \(y\).Why does it works?
- To work for this pretext task, extractor has to understand the concept of the objects depicted in the image. Models must learn to localize salient objects in the image, recognize their orientation and object type, and then relate the object orientation with the dominant orientation that each type of object tends to be depicted within the available images.
- Easy to be implemented by flipping and transpose, no chance for importing low-level visual artifacts so as to avoid trivial features (which have no practical value)
- Operations are easy to be recognized manually.
Experiments
CIFAR: object recognition
- Dataset:
| Datasets | Preprocess |
|---|---|
| CIFAR-10 | Rotations |
- Training: SGD with batch size 128, momentum 0.9, weight decay \(5e−4\) and \(lr\) of 0.1. We drop the learning rates by a factor of 5 after epochs 30, 60, and 80. 100 epochs. Each time feeding with all 4 images.
- Summary
- The learned feature hierarchies: convnet with different number of layers. Representations from the 2nd block are good, and increasing the total depth of the RotNet models leads to increased object recognition performance by the feature maps generated by earlier layers.
- The quality of the learned features w.r.t. the number of recognized rotations: 4 discrete rotations outperform.
- Compared with previous work : almost the same as the NIN supervised model. Fine-tuned the unsupervised learned features further improves the classification performance.
- Correlation between object classification task and rotation prediction task: The representations from pretext make classifier converge faster compared with the classifier trained from scratch.
- Semi-supervised setting: pretrained on the whole dataset without labels, then fine-tuned on a small labeled subset. It exceeds the supervised model when the number of examples per category drops below 1000.
Others: classification, object detection , segmentation
Dataset: ImageNet, Places, and PASCAL VOC.
Task Datasets Classification Pretrained on ImageNet, then test on ImageNet, Places, and PASCAL VOC. Object detection PASCAL VOC Object segmentation PASCAL VOC Backbones: AlexNet without local response normalization units, dropout units, or groups in the colvolutional layers while it includes batch normalization units after each linear layer
Pretrained: on ImageNet, SGD with batch size 192, momentum 0.9, weight decay \(5e − 4\) and \(lr\) of 0.01. Learning rates are dropped by a factor of 10 after epochs 10, and 20 epochs. Trained in total for 30 epochs.
Summary:
ImageNet classification task: surpasses all the other unsupervised methods by a significant margin, narrows the performance gap between unsupervised features and supervised features.
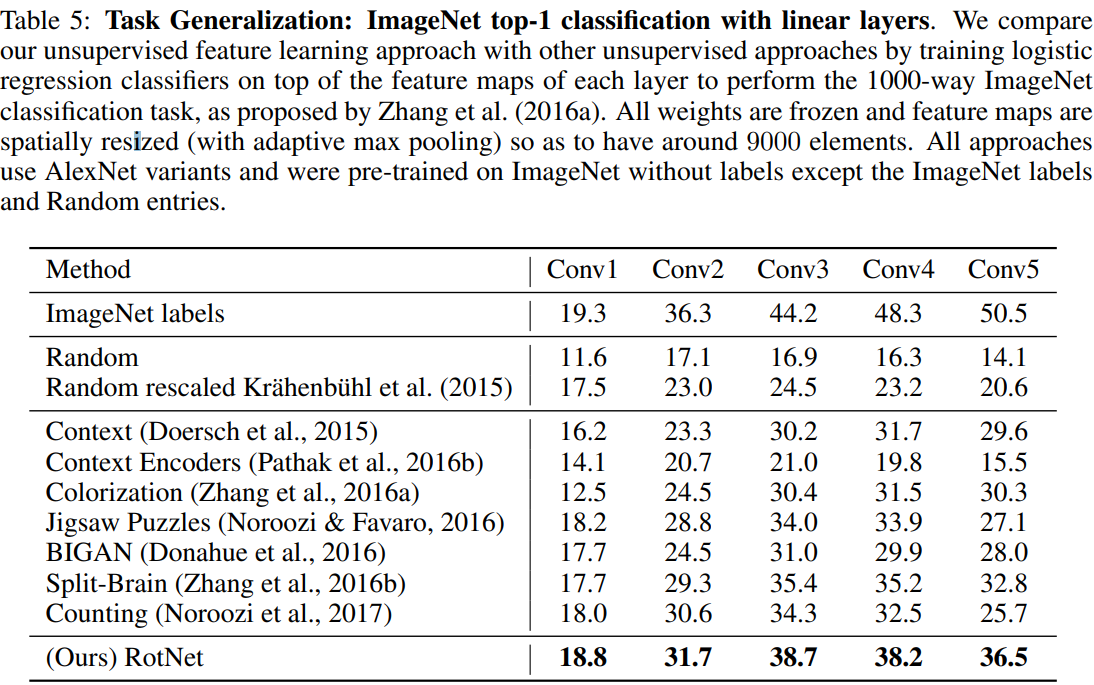
Transfer learning evaluation on PASCAL VOC: fine tuning, used weight rescaling proposed by Krahenbuhl et al.
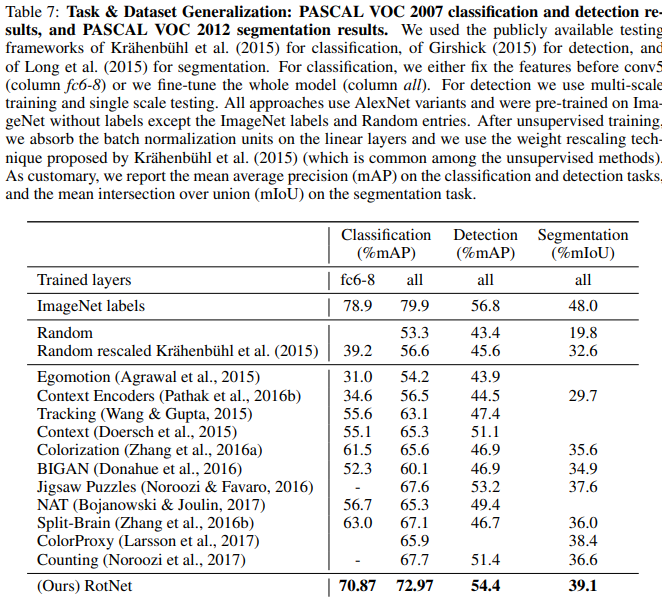
Places classification task: the learnt features are evaluated w.r.t. their generalization on classes that were “unseen” during the unsupervised training phase
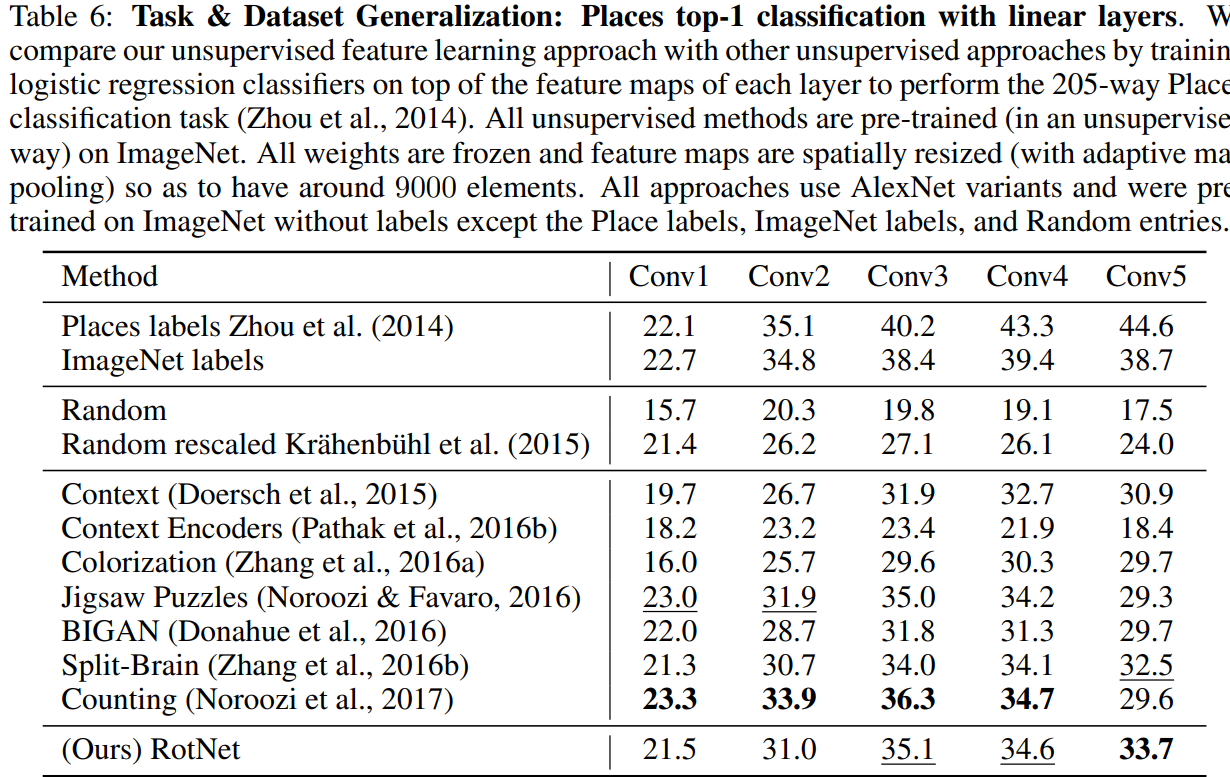
Conclusion
- Propose a new self-supervised task that is very simple and at the same time.
- Rotationsod under various settings (e.g. semi-supervised or transfer learning settings) and in various vision tasks (i.e., CIFAR-10, ImageNet, Places, and PASCAL classification, detection, or segmentation tasks).
- They argue this self-supervised formulation demonstrates state-of-the-art results with dramatic improvements w.r.t. prior unsupervised approaches, and narrows the gap between unsupervised and supervised feature learning.