Paper Unsupervised Visual Representation Learning by Context Prediction
Why?
Previous work
How to get a good image representation
- The latent variables of an appropriate generative model. --> generative models
- But given an image, inferring the latent structure is intractable for even relatively simple models --> to fix, use sampling to perform approximate inference.
- An embedding that can discriminate the semantics in images by distances of them. -- create a supervised "pretext" task. But hard to tell whether the predictions themselves are correct.
- Reconstruction-based: E.g., denoising autoencoders (reconstruction ), sparse autoencoders (reconstruction + sparsity penalty )
- Context prediction: "skip-gram" to "filling the blank" task, and convert the prediction task to discriminate task like discriminating between real images vs. images where one patch has been replaced by a random patch from elsewhere in the dataset. But not hard enough for high-level representations
- Discover object categories using hand-crafted features and various forms of clustering. But they will lose shape information. To keep more shape information, some take contour extraction or defining similarity metrics.
- Video-based: since the identity of objects remains unchanged -
Summary
- Observations
- the difficulties for generalizing CNNs models on Internet -scale datasets
- context has proven to be a powerful source of automatic supervisory signal for learning representations --> context can be regarded as a 'pretext' task to force the model to learn a good word embedding
- current reconstruction-based algorithms struggle with low-level phenomena, like stochastic textures, making it hard to even measure whether a model is generating well.
- Limitations:
- generative models are rather efficiently on smaller datasets but burden on high-resolution natural images
- Some are too simple for extracting high-level representations
- Hard to tell whether the model has obtained good representations.
Goals
Provide a "self-supervised" formulation for image data, a supervised task involving predicting the context for a patch.
How?
Idea
- Hypothesis: Doing well on predicting patches' positions requires understanding scenes and objects--> a good visual representation
- Concretely, sample random pairs of patches in one of eight spatial configurations, and present each pair to a machine learner. The algorithm must then guess the position of one patch relative to the other.
Implementation
Data preparation
Two patches are fed into network
Given an image, one patch will be sampled uniformly, then according to the position of this sampled patch, then 2nd patch will be sampled randomly from the eight possible neighboring locations.
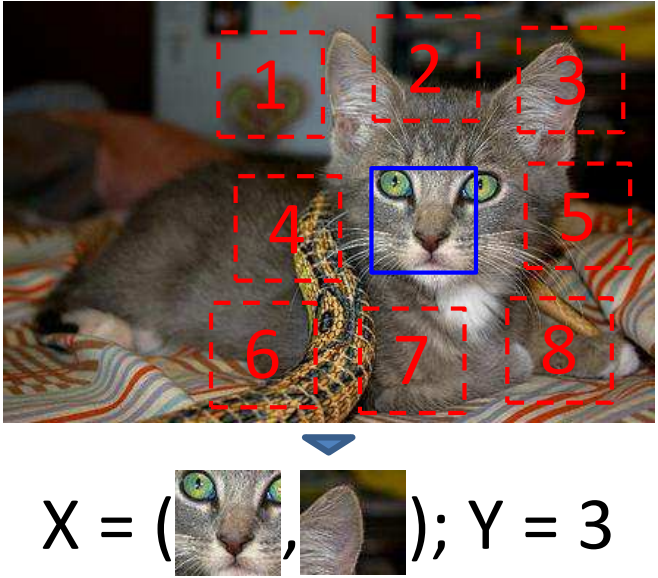
including a gap between patches (patches are not aligned side by side ), also randomly jitter each patch location by up to 7 pixels
For some images ( chromatic aberration), after solving the relative location task (like by detecting the separation between green and magenta (red + blue). ), this problem will be relaxed.
- Shift green and magenta toward gray
- Color dropping : randomly drop 2 of the 3 color channels from each patch and replace them by gaussian noise.
Learning algorithm
Siamese network based on AlexNet. But not all layers share weights, LRN (local response normalization ) layers won't.
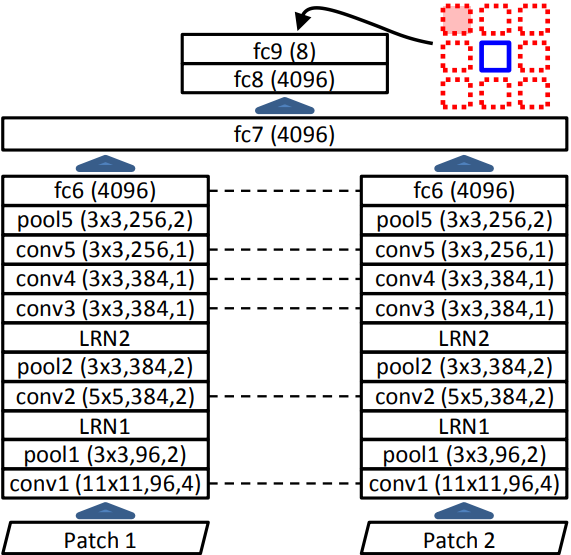
Why does it works?
- Avoid 'trivial' shortcuts (like boundary patterns or textures continuing between patches)--> including a gap (up to 48 pixels) between patches (patches are not aligned side by side ), also randomly jitter each patch location by up to 7 pixels
- Enhancing performance on images with chromatic aberration.
Experiments
Pre-Training: SGD+BN+high momentum, 4 weeks on K40 GPU.
| Datasets | Resizing | Preprocess |
|---|---|---|
| ImageNet | \(150K\sim450K\) total pixels | 1. sample patches at resolution \(96\times 96\) 2. mean subtraction, projecting or dropping colors, and randomly downsampling some patches to as little as 100 total pixels, and then upsampling it. |
Ability on semantic
Does it get similar representations for patches with similar semantics?
check nearest neighbors by normalized correlation of \(fc6\)'s output. Compared with results from random initialized model and ImageNet AlexNet.
Summary
- in a few cases, random (untrained) ConvNet also does reasonably well
- the representations from proposed model often capture the semantic information
Learnability of Chromatic Aberration
- Patches displayed similar aberration tend to be predicted at the same location.
- The effect of color projection operation is canceled for this kind of images.
Object detection
- Dataset : VOC 2007
- Train: fine-tune the pretrained model (model is slight different with the previous one considering the image size in VOC) on VOC 2007.
- Test: output from \(fc7\) is taken.
- Summary
- Pre-trained model outperforms the one trained from scratch
- Obtained the best result on VOC 2007 without using labels
- Robustness of the representations for one object in different datasets: acceptable
Visual data mining
- Task : aims to use a large image collection to discover image fragments which happen to depict the same semantic objects
- Specification for this task: sample a constellation of four adjacent patches from an image, after finding the top 100 images which have the strongest matches for all four patches, then use a type of geometric verification to filter away the images where the four matches are not geometrically consistent. Finally, rank the different constellations by counting the number of times the top 100 matches geometrically verify.
- To define the geometric verification: first compute the best-fitting square \(S\) to the patch centers (via least-squares), while constraining that side of \(S\) be between 2/3 and 4/3 of the average side of the patches. Then compute the squared error of the patch centers relative to \(S\) (normalized by dividing the sum-of-squared-errors by the square of the side of \(S\)). The patch is geometrically verified if this normalized squared error is less than 1.
- Test: VOC 2011, Street View images from Paris
- Summary
- The discovery of birds and torsos is good
- The gains in terms of coverage, suggesting increased invariance for learned features
- The pretext task is difficult: for a large fraction of patches within each image, the task is almost impossible
- Limitations: some loss of purity, and cannot currently determine an object mask automatically (although one could imagine dynamically adding more sub-patches to each proposed object).
Conclusion
- instance-level supervision appears to improve performance on category-level tasks
- The proposed model is sensitive to objects and the layout of the rest of the image