This post is built to list an introduction of reinforce learning, mainly based on the slides given by David Silver. ## Why RL?
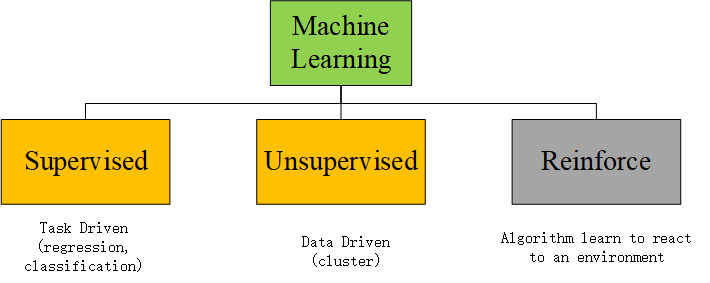
The difference between supervised learning and RL
task directed from fixed data sets vs goal directed learning from interaction
characteristics:
- RL
- trial-and-error search
- delayed reward
- ML
- generalization methods: regularization, data augmentation
- real-time loss
- RL
methods:
- RL
- exploit: get reward
- exploration: make better action selection in the future.
- ML
- discriminative and generative: parameterized and semi-parameterized
- supervised and unsupervised: depends on whether have labeled data
- RL
The capacity of RL
- sequential decision maker facing unknown or known environment
- works for non i.i.d. data
What's RL?
The agent-environment interaction
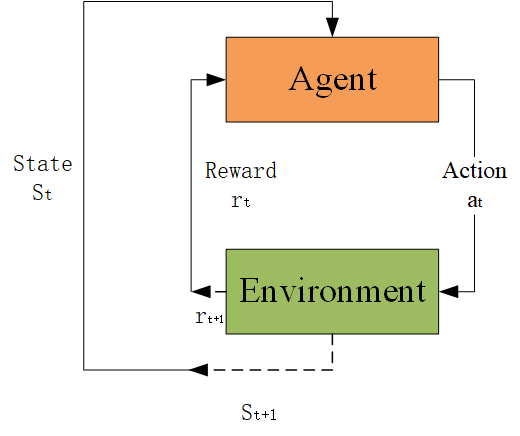
- At each step t the agent:
- Executes action at
- Transform to state St
- Receives scalar reward rt
- The environment:
- Receives action at
- Transform to state St
- Emits scalar reward rt+1
- t increments at env. step
The elements of RL
Policy: agent's behaviour function, mostly is a PDF mapping state to action
Deterministic policy
\[ a = \pi\left(S\right) \]
Stochastic policy
\[ \pi\left(a|S\right)=\mathbb{P}\left(A_t=a|S_t=s\right) \]
Value function: how good is each state and/or action, the scalar value is also named reward.
\[ v_{\pi}\left(s\right)=\mathbb{E}\left(R_{t+1}+\gamma R_{t+1}+{\gamma}^2 R_{t+2}+\cdots|S_t=s\right) \]
Mostly, to make algorithm converge, a final state will be rewarded 0, and other non-final states are rewarded as a minus value.
Model: agent's representation of the environment, they can be modeled by TKinter, gym etc.
e.g.: models in assimilation, maze
\[ \mathcal{P}_{ss'}^{a}=\mathbb{P}\left(S_{t+1}=s'|S_t=s,A_t=a\right)\\ \mathcal{R}_{s}^{a}=\mathbb{E}\left(R_{t+1}=s'|S_t=s,A_t=a\right) \]
unknown environment can be stimulated by sampling ### Classification of RL #### What you want
Value Based: No Policy (Implicit), Value Function
Policy Based: Policy, No Value Function
Actor Critic: Policy, Value Function #### What you knew
Model-free: Policy and/or Value Function, No Model
Model-based: Policy and/or Value Function, Model
How to RL?
Markov process -- to simplify
Markov Process
\[ \mathbb{P}\left(S_{t+1}\right)=\mathbb{P}\left(S_{t+1}|S_1,\cdots,S_t\right)\\ \mathcal{P}_{ss'}=\mathbb{P}\left(S_{t+1}=s'|S_t=s\right) \]
Markov Rewarded Process
\[ \langle S,\mathcal{P},\mathcal{R},\gamma\rangle \] solve the reward from state at time t to the final state, which can be also solved by adding immediate reward and discounted value of successor state.
\[ v\left(s\right)=\mathbb{E}\left(G_t|S_t=s\right)=\mathbb{E}\left(R_{t+1}+\gamma v\left(S_{t+1}|S_t=s\right)\right) \]
Markov Decision Process
\[ \langle S,\mathcal{A},\mathcal{P},\mathcal{R},\gamma\rangle \]
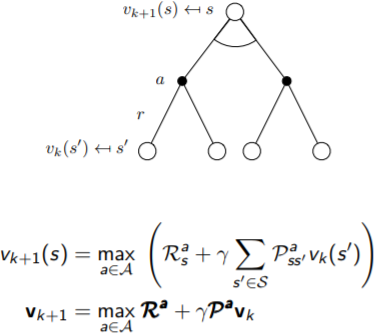
Sequential decision making. * state-value function \[ v_{\pi}\left(s\right)=\mathbb{E}\left(G_t|S_t=s\right) \]
- action-value function \[ q_{\pi}\left(s,a\right)=\mathbb{E}_{\pi}\left(G_t|S_t=s,A_t=a\right) \]
Value?Policy?
Policy Iteration
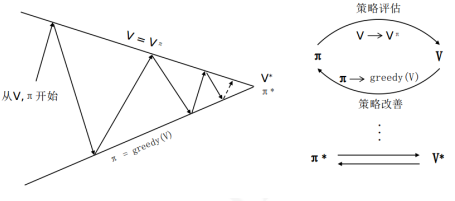
Value Iteration